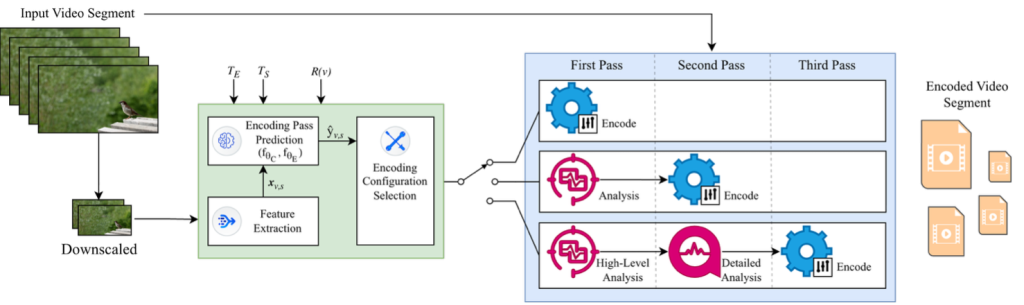
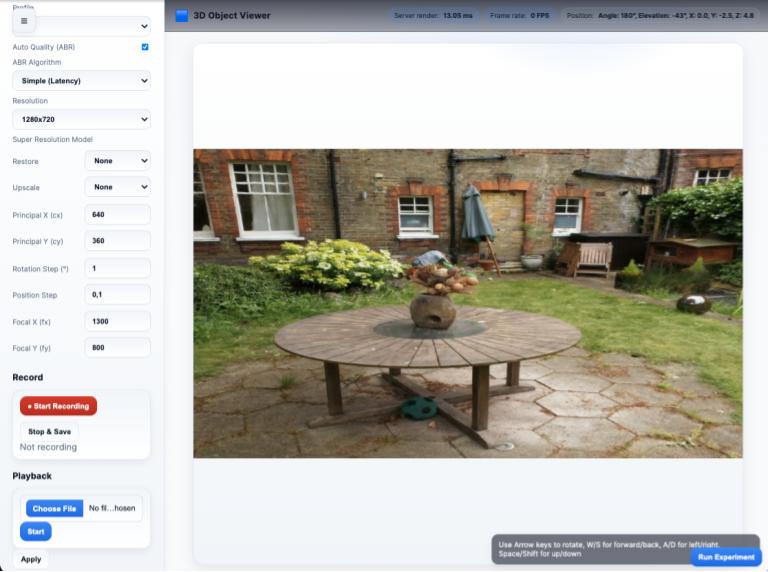
Title: You have a long way to go”: Migrant and Displaced People as Authors in a Storytelling Game Jam
Conference: CHI Play 2026
Authors: Kseniia Harshina, Ameneh Safari, Tom Tucek
Abstract: Games about migration and displacement are often framed through empathy: they invite players to understand experiences of border crossing, bureaucracy, loss, or uncertainty from a safe distance. Yet this framing can become extractive when people with lived experience have little control over how their stories are told, interpreted, or shared. This paper examines a one-day, migrant-led participatory storytelling game jam with adults who had migration and/or displacement experience. We analyze seven shared participant-created game prototypes together with participant reflections, mentor reflections, and process documentation. Our analysis shows how small prototypes used interactive form to express migration as lived constraint, unequal possibility, ongoing change, and layered belonging. It also shows how the workshop conditions shaped what participants could make and how they chose to share, withhold, or continue their work. We argue that participatory storytelling jams should be understood not only through the artifacts they produce, but through the conditions that make authorship possible: participant control over form and disclosure, playtesting as community recognition, and institutional support for the labor behind migrant-led facilitation. The paper contributes an artifact-centered account of a migrant-led storytelling jam and a coding framework for analyzing compact autobiographical games across cases.
AND
Title: Worth the Grind? Player Experiences of Grinding Activities and Mechanics in Games
Conference: CHI Play 2026
Authors: Johannes Ladurner and Kseniia Harshina
Abstract: Grinding is a common but controversial mechanic in video games. Players may criticize grinding as unfair or manipulative; however, they can also experience it as rewarding when it supports meaningful progression and player agency. This work-in-progress paper explores how players describe experiences of grinding in public Reddit discussions. We collected posts and comments from four gaming-related subreddits and analyzed player statements that explained why grinding felt enjoyable, frustrating, or exploitative. The findings suggest that grinding is context-dependent: the same repetitive activity can support or undermine player engagement depending on how it is designed. Based on these themes, we propose six preliminary design implications for player-centered grinding mechanics. These implications have also informed the design of a prototype game, which will be evaluated in future work through playtesting and player interviews.