LumaID: Harnessing Illumination-Awareness for High-Fidelity Video Head Identity Editing
34th ACM International Conference on Multimedia 2026 (ACM MM 2026)
10–14 November 2026
Rio de Janeiro, Brazil
[PDF]
Yiying Wei (AAU, Austria), Xuanhong Chen (Shanghai Jiao Tong University, China), Hadi Amirpour (AAU, Austria), and Christian Timmerer (AAU, Austria)
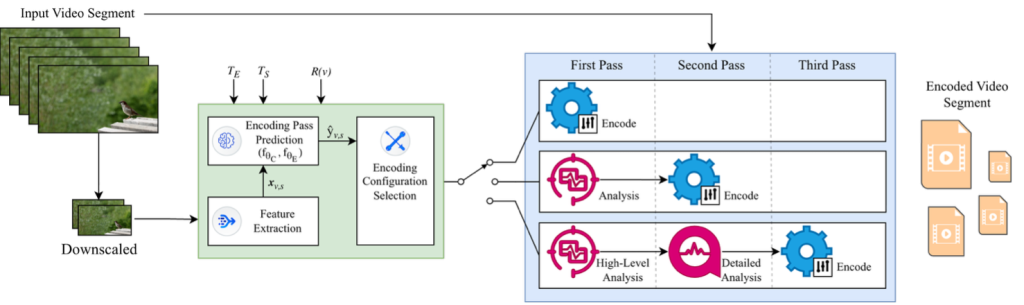
Abstract: Despite yielding higher visual quality than image-to-image approaches, masked generation paradigms for video face editing fundamentally lacks attribute consistency (e.g., illumination, background). We introduce LumaID, a novel framework that explicitly disentangles identity and expression representations from environmental contexts, enabling high-fidelity, fine-grained video head editing while strictly preserving these crucial attributes. At its core, LumaID employs an Omni-Disentangled Diffusion Transformer (OD-DiT) that leverages 3D proxy representations to thoroughly isolate the source and target facial features, fundamentally preventing identity leakage and illumination degradation. To further overcome the distributional drift caused by proxy estimation noise and the lack of explicit consistency supervision, we propose Consist-GRPO. This post-training reinforcement learning mechanism formulates multi-dimensional reward signals (spanning identity, expression, pose, and lighting) to continuously steer the generative process toward strict spatiotemporal alignment. Extensive evaluations demonstrate that LumaID serves as a highly competitive baseline, exhibiting strong performance over prior approaches in both attributes consistency and overall visual quality.