

We’re seeking a passionate researcher for a PhD role in “Efficient Algorithms and Accelerator Architectures for Distributed Edge AI Systems”. This unique position offers the chance to work under the esteemed supervision of Prof. Radu Prodan (AAU Klagenfurt) and Prof. Marcel Baunach (TU Graz), with my guidance at SAL.
https://www.linkedin.com/feed/update/urn:li:activity:7155106482257068032/
What You Will Do:
– Design & implement innovative distributed AI methods and algorithms.
– Customize these methods for the unique constraints of edge devices and networks.
– Investigate novel accelerator architectures for embedded AI applications.
– Explore quantization methods, with a focus on training and fine-tuning on edge devices.
– Publish research in high-impact journals and present at international conferences.
🎓 Candidate Profile:
– Master’s degree in a relevant field.
– Strong in programming and machine learning.
– Excellent communication skills in English.
🌍 Important Residency Note: Applicants should not have resided or carried out main activities in Austria for more than 12 months in the 3 years immediately before the application deadline.
Apply Now! Ensure to follow the specific application process outlined at Crystalline Program Recruitment (link is in the job description). https://lnkd.in/dBCY2xfe

ACM Mile High Video 2024 (mhv), Denver, Colorado, February 11-14, 2024
Authors: Vignesh V Menon, Prajit T Rajendran, Reza Farahani, Klaus Schoffmann, Christian Timmerer
Abstract: The rise in video streaming applications has increased the demand for video quality assessment (VQA). In 2016, Netflix introduced Video Multi-Method Assessment Fusion (VMAF), a full reference VQA metric that strongly correlates with perceptual quality, but its computation is time-intensive. This paper proposes a Discrete Cosine Transform (DCT)-energy-based VQA with texture information fusion (VQ-TIF) model for video streaming applications that determines the visual quality of the reconstructed video compared to the original video. VQ-TIF extracts Structural Similarity (SSIM) and spatiotemporal features of the frames from the original and reconstructed videos and fuses them using a long short-term mem- ory (LSTM)-based model to estimate the visual quality. Experimental results show that VQ-TIF estimates the visual quality with a Pearson Correlation Coefficient (PCC) of 0.96 and a Mean Absolute Error (MAE) of 2.71, on average, compared to the ground truth VMAF scores. Additionally, VQ-TIF estimates the visual quality at a rate of 9.14 times faster than the state-of-the-art VMAF implementation, along with an 89.44 % reduction in energy consumption, assuming an Ultra HD (2160p) display resolution.
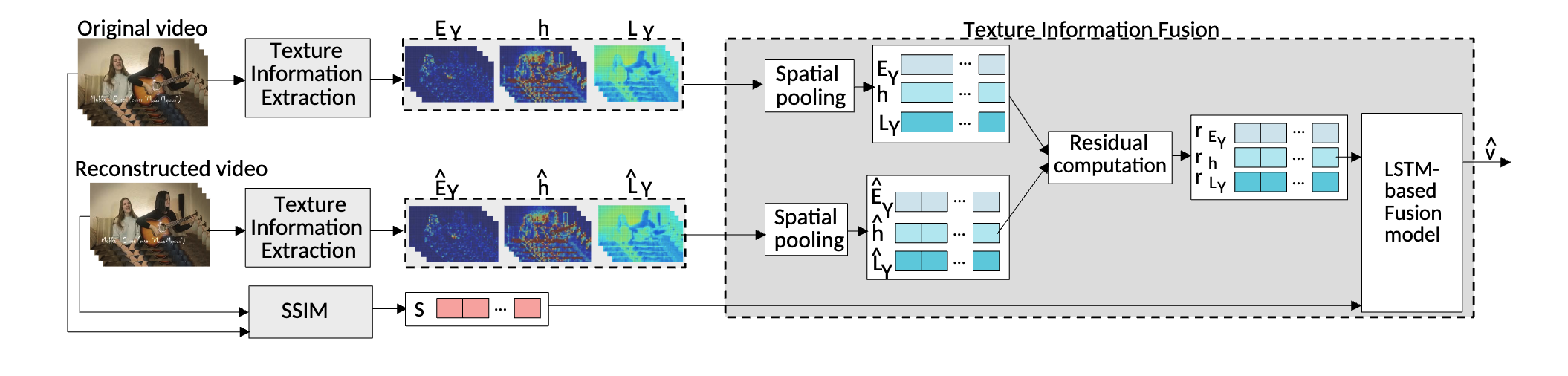

ACM Mile High Video 2024 (mhv), Denver, Colorado, February 11-14, 2024
Authors: Daniele Lorenzi (Alpen-Adria-Universität Klagenfurt, Austria), Minh Nguyen (Alpen-Adria-Universität Klagenfurt, Austria), Farzad Tashtarian (Alpen-Adria-Universität Klagenfurt, Austria), and Christian Timmerer (Alpen-Adria-Universität Klagenfurt, Austria)
Abstract: HTTP Adaptive Streaming (HAS) is the de-facto solution for delivering video content over the Internet. The climate crisis has highlighted the environmental impact of information and communication technologies (ICT) solutions and the need for green solutions to reduce ICT’s carbon footprint. As video streaming dominates Internet traffic, research in this direction is vital now more than ever. HAS relies on Adaptive BitRate (ABR) algorithms, which dynamically choose suitable video representations to accommodate device characteristics and network conditions. ABR algorithms typically prioritize video quality, ignoring the energy impact of their decisions. Consequently, they often select the video representation with the highest bitrate under good network conditions, thereby increasing energy consumption. This is problematic, especially for energy-limited devices, because it affects the device’s battery life and the user experience. To address the aforementioned issues, we propose E-WISH, a novel energy-aware ABR algorithm, which extends the already-existing WISH algorithm to consider energy consumption while selecting the quality for the next video segment. According to the experimental findings, E-WISH shows the ability to improve Quality of Experience (QoE) by up to 52% according to the ITU-T P.1203 model (mode 0) while simultaneously reducing energy consumption by up to 12% with respect to state-of-the-art approaches.
Keywords: HTTP adaptive streaming, Energy, Adaptive Bitrate (ABR), DASH

On Wednesday, December 20, 2023, Josef Hammer successfully defended his PhD thesis (“Transparent Access to 5G Edge Services”) under the supervision of Univ.-Prof. DI Dr. Hermann Hellwagner and Univ.-Prof. DI Dr. Radu Prodan. The defense was chaired by Assoc.-Prof. DI Dr. Klaus Schöffmann and the examiners were Prof. Dr.-Ing. Amr Rizk (Universität Duisburg-Essen) and Univ.-Prof. Dipl.-Ing. Dr. Christian Timmerer. We are pleased to congratulate Dr. Josef Hammer on passing his Ph.D. exam!


In a noteworthy presence at the 16th IEEE/ACM International Conference on Utility and Cloud Computing (UCC 2023), Dragi Kimovski and Narges Mehran presented three workshop papers:
Additionally, Dragi Kimovski took on the role of a session chair, leading discussions on the intricacies of scheduling in the computing continuum.


Ran from December 15 to 17, 2023
Website: https://klujam.at/
With 165 registered participants and 35 games submitted, this was the largest game jam hosted in Klagenfurt to date!
A warm thank you to everyone who participated and/or helped – this event was a big success.
Same as every semester, students, teachers, alumni, and externals all worked together, formed teams, and made various games within 48 hours. We also had many international online participants joining us, e.g. from the Netherlands or even from Brazil.
This time, the topic was “Caution Fragile”, which was interpreted in different ways – from detective stories, board games and, pen-and-paper games, VR games, to classical arcade video games, the results were more varied than ever!
Please feel free to check out all the games here:
https://itch.io/jam/7th-winter-game-jam/entries
A final shoutout to Dynatrace, Plincs, Sensolligent, Fire Totem Games, Dirty Paws Studio, the FTF and the University for making this possible!



Our paper has been accepted at ICASSP 2024:
Mohammad Ghasempour (AAU, Austria), Hadi Amirpour (AAU, Austria), Mohammad Ghanbari (University of Essex, UK), and Christian Timmerer (AAU, Austria)
Abstract: With the ubiquity of video streaming, optimizing the delivery of video content while reducing energy consumption has become increasingly critical. Traditional adaptive streaming relies on a fixed set of bitrate-resolution pairs, known as bitrate ladders, for encoding. However, this one-size-fits-all approach is suboptimal for diverse video content. As a result, per-title encoding approaches dynamically select the bitrate ladder for each content. In this paper, we address the pressing issue of increasing energy consumption in video streaming by introducing GreenRes, a novel approach that goes beyond traditional quality-centric resolution selection. Instead, GreenRes considers both video quality and energy consumption to construct an optimal bitrate ladder tailored to the unique characteristics of each video content.
To achieve this, GreenRes, similar to per-title encoding, encodes each video content at various resolutions, each with a set of bitrates. It then establishes a maximum acceptable quality drop threshold and selects resolutions that not only maintain video quality above this threshold, but also minimize energy consumption. Our experimental results demonstrate a 30.82% reduction in energy consumption on average, while ensuring a maximum quality drop of 0.53 Video Multimethod Assessment Fusion (VMAF) points.
Funded by the EU, HiPEAC (High-Performance Edge And Cloud computing) is the premier focal point for networking, dissemination, training, and collaboration activities in Europe for researchers, industry, and policy related to computing systems.
The HiPEAC webinar series allows you to keep up to date on the latest advances in computer architecture and compilation research via online sessions, which can be accessed anywhere.
The Graph-Massivizer Project webinar took place on November 29, 2023. After an introduction by Nuria De Lama, Radu Prodan presented the background of GraphProcessing, from Euler‘s five-node graphs to the massive graphs of today, and the motivations for the project.
Project details have been presented by Reza Farahani and Matteo Angelinelli.
WEBINAR is online now: https://www.youtube.com/watch?v=YW7pD6nPMhs


At Christian Doppler Laboratory ATHENA, we offer an internship*)**) for 2024 for Master Students, and we kindly request your applications by the 19th of January 2024 with the following data (in German or English):
*) A 3 months period in 2024 (with an exact time slot to be discussed) with the possibility to spend up to 1-month at the industrial partner; 20h per week “Universitäts-KV, Verwendungsgruppe C1, studentische Hilfskraft”
**) Depending on whether the funding gets approval from the CDG.
Please send your application by email to christian.timmerer@aau.at.
About ATHENA: The Christian Doppler laboratory ATHENA (AdapTive Streaming over HTTP and Emerging Networked MultimediA Services) is jointly proposed by the Institute of Information Technology (ITEC; http://itec.aau.at) at Alpen-Adria-Universität Klagenfurt (AAU) and Bitmovin GmbH (https://bitmovin.com) to address current and future research and deployment challenges of HAS and emerging streaming methods. AAU (ITEC) has been working on adaptive video streaming for more than a decade, has a proven record of successful research projects and publications in the field, and has been actively contributing to MPEG standardization for many years, including MPEG-DASH; Bitmovin is a video streaming software company founded by ITEC researchers in 2013 and has developed highly successful, global R&D and sales activities and a world-wide customer base since then.
The aim of ATHENA is to research and develop novel paradigms, approaches, (prototype) tools, and evaluation results for the phases
The new approaches and insights are to enable Bitmovin to build innovative applications and services to account for the steadily increasing and changing multimedia traffic on the Internet.
![]()