Title: From Latency to Engagement: Technical Synergies and Ethical Questions in IoT-Enabled Gaming
Authors: Kurt Horvath, Tom Tucek
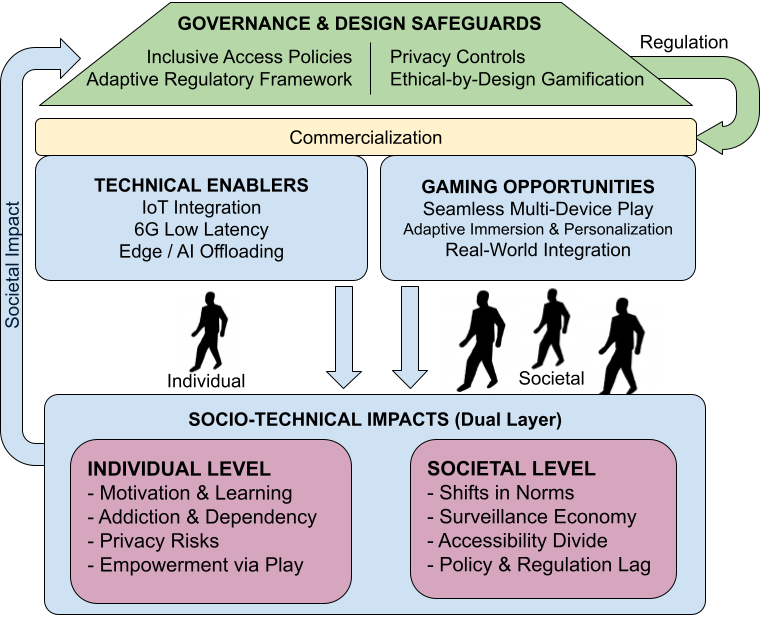
Abstract: The convergence of video games with the Internet of Things (IoT), artificial intelligence (AI), and emerging 6G networks creates unprecedented opportunities and pressing challenges. On a technical level, IoT-enabled gaming requires ultra-low latency, reliable quality of service (QoS), and seamless multi-device integration supported by edge and cloud intelligence. On a societal level, gamification increasingly extends into education, health, and commerce, where points, badges, and immersive feedback loops can enhance engagement but also risk manipulation, privacy violations, and dependency. This position paper examines these dual dynamics by linking technical enablers, such as 6G connectivity, IoT integration, and edge/AI offloading, with ethical concerns surrounding behavioral influence, data usage, and accessibility. We propose a comparative perspective that highlights where innovation aligns with user needs and where safeguards are necessary. We identify open research challenges by combining technical and ethical analysis and emphasize the importance of regulatory and design frameworks to ensure responsible, inclusive, and sustainable IoT-enabled gaming.
Overview – 1st Workshop on Intelligent and Scalable Systems across the Computing Continuum