Authors: Emanuele Artioli (Alpen-Adria Universität Klagenfurt, Austria), Daniele Lorenzi (Alpen-Adria Universität Klagenfurt, Austria), Farzad Tashtarian (Alpen-Adria Universität Klagenfurt, Austria), Christian Timmerer (Alpen-Adria Universität Klagenfurt, Austria)
Event: ACM 4th Mile-High Video Conference (MHV’25), 18–20 February 2025 |
Denver, CO, USA
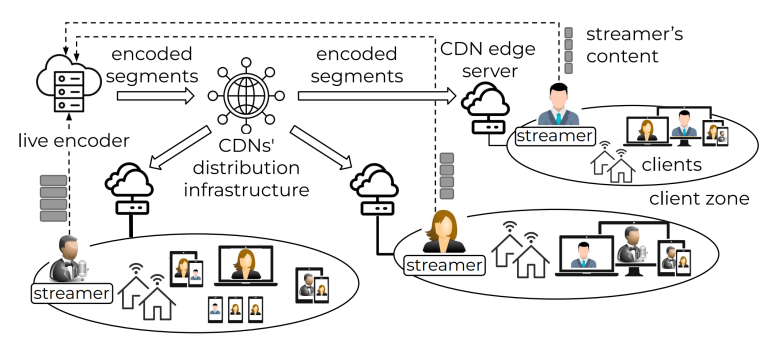
Abstract: The demand for accessible, multilingual video content has grown significantly with the global rise of streaming platforms, social media, and online learning. The traditional solutions for making content accessible across languages include subtitles, even generated ones, as YouTube offers, and synthesizing voiceovers, offered, for example, by the Yandex Browser. Subtitles are cost-effective and reflect the original voice of the speaker, which is often essential for authenticity. However, they require viewers to divide their attention between reading text and watching visuals, which can diminish engagement, especially for highly visual content. Synthesized voiceovers, on the other hand, eliminate this need by providing an auditory translation. Still, they typically lack the emotional depth and unique vocal characteristics of the original speaker, which can affect the viewing experience and disconnect audiences from the intended pathos of the content. A straightforward solution would involve having the original actor “perform” in every language, thereby preserving the traits that define their character or narration style. However, recording actors in multiple languages is impractical, time-intensive, and expensive, especially for widely distributed media.
By leveraging generative AI, we aim to develop a client-side tool, to incorporate in a dedicated video streaming player, that combines the accessibility of multilingual dubbing with the authenticity of the original speaker’s performance, effectively allowing a single actor to deliver their voice in any language. To the best of our knowledge, no current streaming system can capture the speaker’s unique voice or emotional tone.