

Authors: Natalia Sokolova, Mario Taschwer, Stephanie Sarny, Doris Putzgruber-Adamitsch and Klaus Schoeffmann
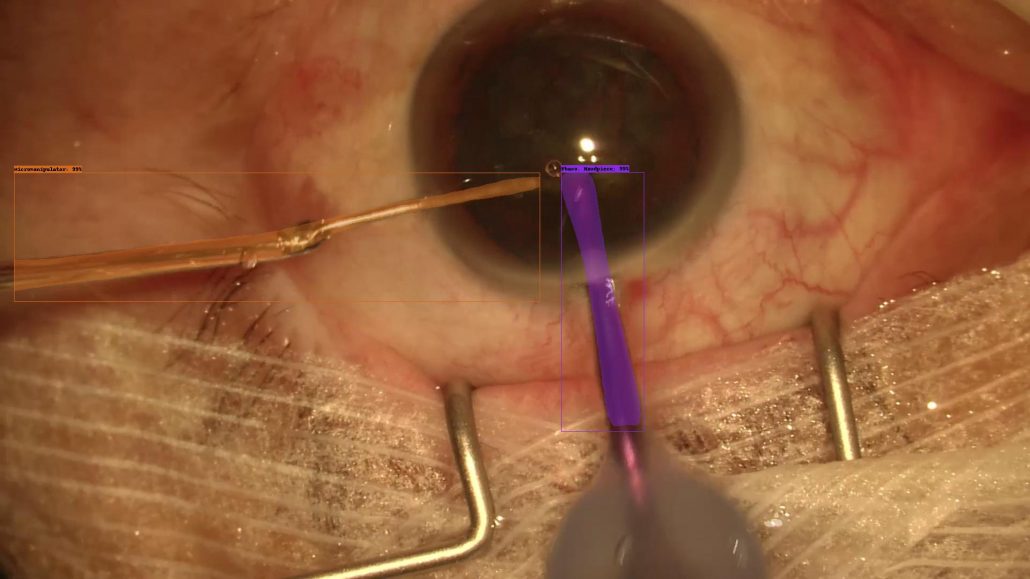
Abstract: Automatically detecting clinically relevant events in surgery video recordings is becoming increasingly important for documentary, educational, and scientific purposes in the medical domain. From a medical image analysis perspective, such events need to be treated individually and associated with specific visible objects or regions. In the field of cataract surgery (lens replacement in the human eye), pupil reaction (dilation or restriction) during surgery may lead to complications and hence represents a clinically relevant event. Its detection requires automatic segmentation and measurement of pupil and iris in recorded video frames. In this work, we contribute to research on pupil and iris segmentation methods by (1) providing a dataset of 82 annotated images for training and evaluating suitable machine learning algorithms, and (2) applying the Mask R-CNN algorithm to this problem, which – in contrast to existing techniques for pupil segmentation – predicts free-form pixel-accurate segmentation masks for iris and pupil.
The proposed approach achieves consistent high segmentation accuracies on several metrics while delivering an acceptable prediction efficiency, establishing a promising basis for further segmentation and event detection approaches on eye surgery videos.





 VBS 2020 in Daejeon (South Korea) was an amazing event with a lot of fun! Eleven teams, each consisting of two users (coming from 11 different countries) competed against each other in both a private session for about 5 hours and a public session for almost 3 hours. ITEC did also participate with two teams. In total all teams had to solve 22 challenging video retrieval tasks, issued on a shared dataset consisting of 1000 hours of content (V3C1)! Many thanks go to the VBS teams but also to the VBS organizers as well as the local organizers, who did a great job and made VBS2020 a wonderful and entertaining event!
VBS 2020 in Daejeon (South Korea) was an amazing event with a lot of fun! Eleven teams, each consisting of two users (coming from 11 different countries) competed against each other in both a private session for about 5 hours and a public session for almost 3 hours. ITEC did also participate with two teams. In total all teams had to solve 22 challenging video retrieval tasks, issued on a shared dataset consisting of 1000 hours of content (V3C1)! Many thanks go to the VBS teams but also to the VBS organizers as well as the local organizers, who did a great job and made VBS2020 a wonderful and entertaining event!

 Sabrina Kletz presented the paper “Learning the Representation of Instrument Images in Laparoscopy Video” at the
Sabrina Kletz presented the paper “Learning the Representation of Instrument Images in Laparoscopy Video” at the 
