diveXplore – An Open-Source Software for Modern Video Retrieval with Image/Text Embeddings
ACM Multimedia 2025
October 27 – October 31, 2025
Dublin, Ireland
[PDF]
Mario Leopold (AAU, Austria), Farzad Tashtarian (AAU, Austria), Klaus Schöffmann (AAU, Austria)
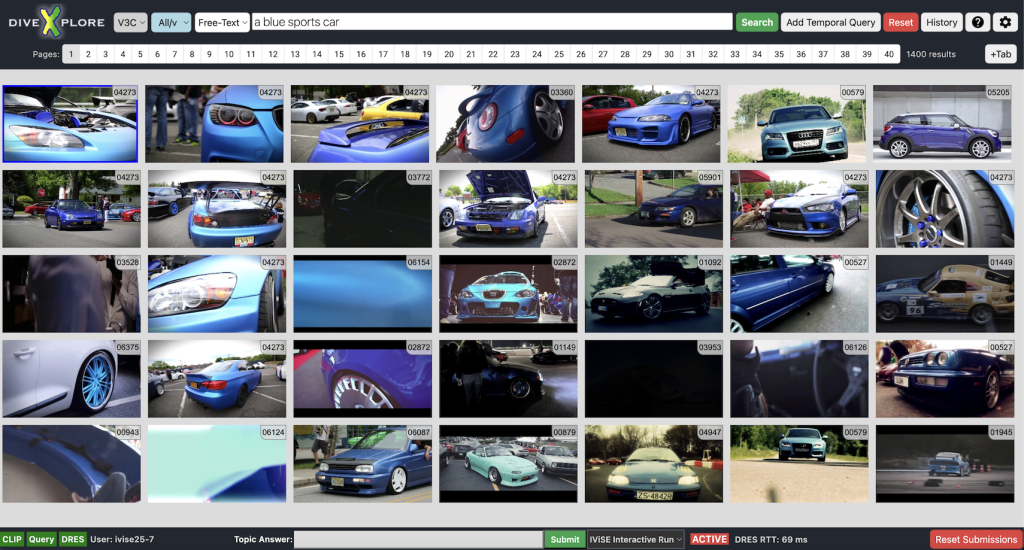
Abstract:Effective video retrieval in large-scale datasets presents a significant challenge, with existing tools often being too complex, lacking sufficient retrieval capabilities, or being too slow for rapid search tasks. This paper introduces diveXplore, an open-source software designed for interactive video retrieval. Due to its success in various competitions like the Video Browser Showdown (VBS) and the Interactive Video Retrieval 4 Beginners (IVR4B), as well as its continued development since 2017, diveXplore is a solid foundation for various kinds of retrieval tasks. The system is built on a three-layer architecture, comprising a backend for offline preprocessing, a middleware with a Node.js and Python server for query handling, and a MongoDB for metadata storage, as well as an Angular-based frontend for user interaction. Key functionalities include free-text search using natural language, temporal queries, similarity search, and other specialized search strategies. By open-sourcing diveXplore, we aim to establish a solid baseline for future research and development in the video retrieval community, encouraging contributions and adaptations for a wide range of use cases, even beyond competitive settings.