Authors: Hadi Amirpour (AAU, Austria), Mohammad Ghasempour (AAU, Austria), Farzad Tashtarian (AAU, Austria), Ahmed Telili (TII, UAE), Samira Afzal (AAU, Austria), Wassim Hamidouche (INSA, France), Christian Timmerer (AAU, Austria)
Conference: IEEE Visual Communications and Image Processing (IEEE VCIP 2024) – Tokyo, Japan, December 8-11, 2024
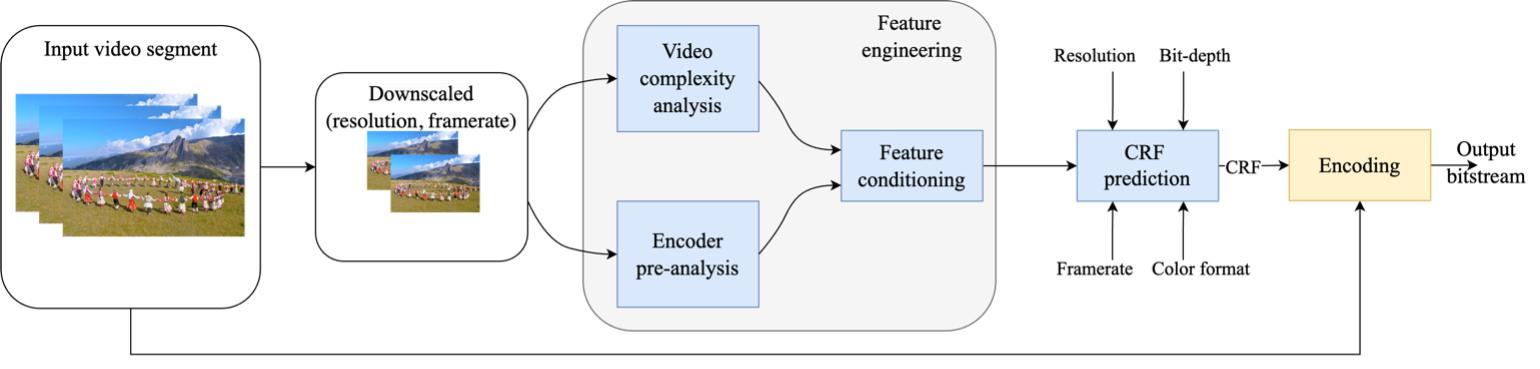
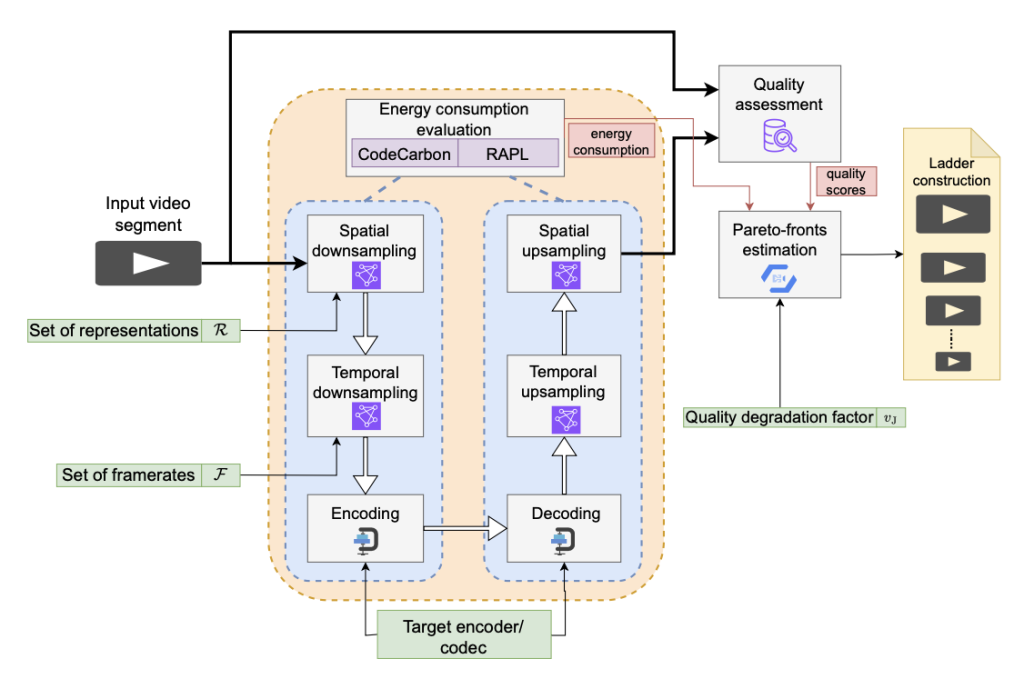
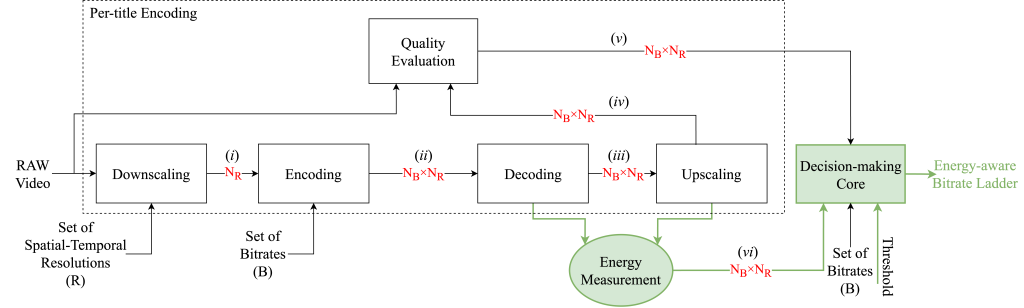
Abstract: In the field of video streaming, the optimization of video encoding and decoding processes is crucial for delivering high-quality video content. Given the growing concern about carbon dioxide emissions, it is equally necessary to consider the energy consumption associated with video streaming. Therefore, to take advantage of machine learning techniques for optimizing video delivery, a dataset encompassing the energy consumption of the encoding and decoding process is needed. This paper introduces a comprehensive dataset featuring diverse video content, encoded and decoded using various codecs and spanning different devices. The dataset includes 1000 videos encoded with four resolutions (2160p, 1080p, 720p, and 540p) at two frame rates (30 fps and 60 fps), resulting in eight unique encodings for each video. Each video is further encoded with four different codecs — AVC (libx264), HEVC (libx265), AV1 (libsvtav1), and VVC (VVenC) — at four quality levels defined by QPs of 22, 27, 32, and 37. In addition, for AV1, three additional QPs of 35, 46, and 55 are considered. We measure both encoding and decoding time and energy consumption on various devices to provide a comprehensive evaluation, employing various metrics and tools. Additionally, we assess encoding bitrate and quality using quality metrics such as PSNR, SSIM, MS-SSIM, and VMAF. All data and the reproduction commands and scripts have been made publicly available as part of the dataset, which can be used for various applications such as rate and quality control, resource allocation, and energy-efficient streaming.
Dataset URL: https://github.com/cd-athena/MVCD
Index Terms— Video encoding, decoding, energy, complexity, quality.