

Distributed and Parallel Systems

Athors: Alexander Lercher, Nishant Saurabh, Radu Prodan
The 15th IEEE International Conference on Social Computing and Networking
http://www.swinflow.org/confs/2022/socialcom/
Abstract: Community evolution prediction enables business-driven social networks to detect customer groups modeled as communities based on similar interests by splitting them into temporal segments and utilizing ML classification to predict their structural changes. Unfortunately, existing methods overlook business contexts and focus on analyzing customer activities, raising privacy concerns. This paper proposes a novel method for community evolution prediction that applies a context-aware approach to identify future changes in community structures through three complementary features. Firstly, it models business events as transactions, splits them into explicit contexts, and detects contextualized communities for multiple time windows. Secondly, it %it performs feature engineering by uses novel structural metrics representing temporal features of contextualized communities. Thirdly, it uses extracted features to train ML classifiers and predict the community evolution in the same context and other dependent contexts. Experimental results on two real-world data sets reveal that traditional ML classifiers using the context-aware approach can predict community evolution with up to three times higher accuracy, precision, recall, and F1-score than other baseline classification methods (i.e., majority class, persistence).

2022 IEEE/ACM 2nd Workshop on Distributed Machine Learning for the Intelligent Computing Continuum (DML-ICC) In conjuction with IEEE/ACM UCC 2022 December 6-9, 2022 | Vancouver, Washington, USA
Authors: Narges Mehran (Alpen-Adria-Universität Klagenfurt) and Radu Prodan (Alpen-Adria-Universität Klagenfurt)
Abstract: Processing rapidly growing data encompasses complex workflows that utilize the Cloud for high-performance computing and the Fog and Edge devices for low-latency communication. For example, autonomous driving applications require inspection, recognition, and classification of road signs for safety inspection assessments, especially on crowded roads. Such applications are among the famous research and industrial exploration topics in computer vision and machine learning. In this work, we design a road sign inspection workflow consisting of 1) encoding and framing tasks of video streams captured by camera sensors embedded in the vehicles, and 2) convolutional neural network (CNN) training and inference models for accurate visual object recognition. We explore a matching theoretic algorithm named CODA [1] to place the workflow on the computing continuum, targeting the workflow processing time, data transfer intensity, and energy consumption as objectives. Evaluation results on a real computing continuum testbed federated among four Cloud, Fog, and Edge providers reveal that CODA achieves 50%-60% lower completion time, 33%-59% lower CO2 emissions, and 19%-45% lower data transfer intensity compared to two stateof-the-art methods.

OTEC: An Optimized Transcoding Task Scheduler for Cloud and Fog Environments
Samira Afzal (Alpen-Adria-Universität Klagenfurt), Farzad Tashtarian (Alpen-Adria-Universität Klagenfurt), Hamid Hadian (Alpen-Adria-Universität Klagenfurt), Alireza Erfanian (Alpen-Adria-Universität Klagenfurt), Christian Timmerer (Alpen-Adria-Universität Klagenfurt), and Radu Prodan (Alpen-Adria-Universität Klagenfurt)
Abstract:
Encoding and transcoding videos into multiple codecs and representations is a significant challenge that requires seconds or even days on high-performance computers depending on many technical characteristics, such as video complexity or encoding parameters. Cloud computing offering on-demand computing resources optimized to meet the needs of customers and their budgets is a promising technology for accelerating dynamic transcoding workloads. In this work, we propose OTEC, a novel multi-objective optimization method based on the mixed-integer linear programming model to optimize the computing instance selection for transcoding processes. OTEC determines the type and number of cloud and fog resource instances for video encoding and transcoding tasks with optimized computation cost and time. We evaluated OTEC on AWS EC2 and Exoscale instances for various administrator priorities, the number of encoded video segments, and segment transcoding times. The results show that OTEC can achieve appropriate resource selections and satisfy the administrator’s priorities in terms of time and cost minimization.
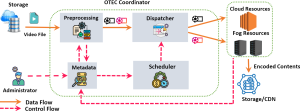
OTEC architecture overview.

As a Hipeac member, we are hosting Zeinab Bakhshi, a Ph.D. student from Mälardalens University in Sweden. Zeinab achieved a Hipeac collaboration grant and is now hosted by Profesor Radu Prodan to expand her research on container-based fog architectures. Taking advantage of the multi-layer continuum computing architecture in Klagenfurt lab helps Zeinab deploy the use case she is researching on. These scientific experiments take her research work to the next level. We are planning to publish our collaborative research work in a series of papers based on the upcoming results.





 DataCloud will research and develop novel methods to support the complete lifecycle of #BigData pipelines processing.Follow us to know more about #datacloud2020
DataCloud will research and develop novel methods to support the complete lifecycle of #BigData pipelines processing.Follow us to know more about #datacloud2020Title: MOGPlay: A Decentralized Crowd Journalism Application for Democratic News Production
Authors: Ines Rito Lima, Claudia Marinho,Vasco Filipe, Alexandre Ulisses, Nishant Saurabh, Antorweep Chakravorty, Zhiming Zhao, Atanas Hristov, Radu Prodan
2022 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM)
Abstract: Media production and consumption behaviors are changing in response to new technologies and demands, giving birth to a new generation of social applications. Among them, crowd journalism represents a novel way of constructing democratic and trustworthy news relying on ordinary citizens arriving at breaking news locations and capturing relevant videos using their smartphones. The ARTICONF project proposes a trustworthy, resilient, and globally sustainable toolset for developing decentralized applications (DApps). Leveraging the ARTICONF tools, we introduce a new DApp for crowd journalism called MOGPlay. MOGPlay collects and manages audio-visual content generated by citizens and provides a secure blockchain platform that rewards all stakeholders involved in professional news production. Besides live streaming, MOGPlay offers a marketplace for audio-visual content trading among citizens and free journalists with an internal token ecosystem. We discuss the functionality and implementation of the MOGPlay DApp and illustrate three pilot crowd journalism live scenarios that validate the prototype.
Titel: CardioHPC: Serverless Approaches for Real-Time Heart Monitoring of Thousands of Patients
Authors: Marjan Gusev, Sashko Ristov, Andrei Amza, Armin Hohenegger, Radu Prodan, Dimitar Mileski, Pano Gushev, Goran Temelkov
17th Workshop on Workflows in Support of Large-Scale Science
Abstract: We analyze a heart monitoring center for patients wearing electrocardiogram sensors outside hospitals. This prevents serious heart damages and increases life expectancy and health-care efficiency. In this paper, we address a problem to provide a scalable infrastructure for the real-time processing scenario for at least 10000 patients simultaneously, and efficient fast processing architecture for the postponed scenario when patients upload data after realized measurements. CardioHPC is a project to realize a simulation of these two scenarios using digital signal processing algorithms and artificial intelligence-based detection and classification software for automated reporting and alerting. We elaborate the challenges we met in experimenting with different serverless implementations: 1) container-based on Google Cloud Run, and 2) Function-as-a-Service (FaaS) on AWS Lambda. Experimental results present the effect of overhead in the request and transfer time, and speedup achieved by analyzing the response time and throughput on both container-based and FaaS implementations as serverless workflows.
Titel: SimLess: Simulate Serverless Workflows and Their Twins and Siblings in Federated FaaS
Authors: Sashko Ristov, Mika Hautz, Christian Hollaus, Radu Prodan
2022 ACM Symposium on Cloud Computing
Abstract: Many researchers migrate scientific serverless workflows or function choreographies (FC) on Function-as-a-Service (FaaS) to benefit from its high scalability and elasticity. Unfortunately, the heterogeneous nature of federated FaaS hampers decisions on the most appropriate configuration setup to run FCs. Consequently, scientists must choose between accurate but tedious and expensive experiments or simple but cheap but less accurate simulations. Unfortunately, related work mainly supports either simulation models for serverfull workflow applications that run on virtual machines and containers or partial FaaS models for individual serverless functions that focus on execution time and neglect various kinds of federated FaaS overheads. Therefore, this paper introduces SimLess, an FC simulation framework across multiple FaaS providers to achieve accurate FC simulations with a simple and cheap parameter setup. Unlike the costly approaches that use machine learning over time series to predict the behavior of FCs, SimLess introduces two light concepts: (1) twins, representing the same code deployed with the same computing, communication, and storage resources, but in other cloud regions of the same FaaS provider, and (2) siblings, representing the same code deployed in the same region with different computing resources. The novel SimLess simulation model splits the round trip time of a function into several parameters reused among twins and siblings without running them. We evaluated SimLess with two scientific FCs deployed across 18 AWS, Google, and IBM regions. SimLess simulates the cumulative overhead with an average inaccuracy of 8.9% without significant differences between regions for learning and validation. Moreover, SimLess generates an inaccuracy of up to 9.75% for a low concurrency FC executed on a single region, with high concurrency of 2500 functions executed in other regions. Finally, SimLess reduces the parameter setup cost by 77.23% compared to the existing simulation approaches.



Student travel award at IEEE Cluster 2022
Narges Mehran got the student award for presenting the paper titled “Matching-based Scheduling of Asynchronous Data Processing Workflows on the Computing Continuum” at IEEE Cluster 2022.
The presentation was on the 7th of September: https://clustercomp.org/2022/program/

