
ALIS’22: Artificial Intelligence for Live Video Streaming
colocated with ACM Multimedia 2022
October 2022, Lisbon, Portugal
{kind=link}


March 01-03, 2022 | Denver, CO, USA
After running as an independent event for several years, 2022 was the first year where Mile-High Video Conference (MHV) was organized by the ACM Special Interest Group on Multimedia (SIGMM). ACM MHV is a unique forum for participants from both industry and academia to present, share, and discuss innovations and best practices from multimedia content production to consumption.
This year, MHV hosted around 270 on-site participants and more than 2000 online participants from academia and industry. Five ATHENA members travelled to Denver, USA, to present two full papers and four short papers in MHV 2022.




Here is a list of full papers presented in MHV:
Super-resolution Based Bitrate Adaptation for HTTP Adaptive Streaming for Mobile Devices: The advancement of mobile hardware in recent years made it possible to apply deep neural network (DNN) based approaches on mobile devices. This paper introduces a lightweight super-resolution (SR) network deployed at mobile devices and a novel adaptive bitrate (ABR) algorithm that leverages SR networks at the client to improve the video quality. More …
Take the Red Pill for H3 and See How Deep the Rabbit Hole Goes: With the introduction of HTTP/3 (H3) and QUIC at its core, there is an expectation of significant improvements in Web-based secure object delivery. An important question is what H3 will bring to the table for such services. To answer this question, we present the new features of H3 and QUIC, and compare them to those of H/1.1/2 and TCP. More …
Here is a list of short papers presented in MHV:
RICHTER: hybrid P2P-CDN architecture for low latency live video streaming: RICHTER leverages existing works that have combined the characteristics of Peer-to-Peer (P2P) networks and CDN-based systems and introduced a hybrid CDN-P2P live streaming architecture. [PDF]
CAdViSE or how to find the sweet spots of ABR systems: CAdViSE provides a Cloud-based Adaptive Video Streaming Evaluation framework for the automated testing of adaptive media players. [PDF]
Video streaming using light-weight transcoding and in-network intelligence: LwTE reduces HTTP Adaptive Streaming (HAS) streaming costs by enabling lightweight transcoding at the edge. [PDF]
Efficient bitrate ladder construction for live video streaming: This paper introduces an online bitrate ladder construction scheme for live video streaming applications using Discrete Cosine Transform (DCT)-energy-based low-complexity spatial and temporal features. [PDF]

The first edition of “Security and Privacy Issues in Internet of Medical Things”, co-edited by Radu Prodan, will be published in May 2022 by Elsevier.
More information is available HERE.


Title: FaaScinating Resilience for Serverless Function Choreographies in Federated Clouds
Authors: Sasko Ristov, Dragi Kimovski, Thomas Fahringer
Abstract: Cloud applications often benefit from deployment on serverless technology Function-as-a-Service (FaaS), which may instantly spawn numerous functions and charge users for the period when serverless functions are running. Maximum benefit is achieved when functions are orchestrated in a workflow or function choreographies (FCs). However, many provider limitations specific for FaaS, such as maximum concurrency or duration often increase the failure rate, which can severely hamper the execution of entire FCs. Current support for resilience is often limited to function retries or try-catch, which are applicable within the same cloud region only. To overcome these limitations, we introduce rAF CL, a middleware platform that maintains the reliability of complex FCs in federated clouds. In order to support resilient FC execution under rAF CL, our model creates an alternative strategy for each function based on the required availability specified by the user. Alternative strategies are not restricted to the same cloud region, but may contain alternative functions across five providers, invoked concurrently in a single alternative plan or executed subsequently in multiple alternative plans. With this approach, rAF CL offers flexibility in terms of cost-performance trade-off. We evaluated rAF CL by running three real-life applications across three cloud providers. Experimental results demonstrated that rAF CL outperforms the resilience of AWS Step Functions, increasing the success rate of the entire FC by 53.45%, while invoking only 3.94% more functions with zero wasted function invocations. rAF CL significantly improves the availability of entire FCs to almost 1 and survives even after massive failures of alternative functions

Project Lead: H. Hellwagner, Ch. Timmerer
Abstract: Immersive telepresence technologies will have game-changing impacts on interactions amongst individuals or with non-human objects (e.g. machines), in cyberspace with blurred boundaries between the virtual and physical world. The impacts of this technology are expected to range in a variety of vertical sectors, including education and training, entertainment, healthcare, manufacturing industry, etc. The key challenges include limitations of both the application platform and the underlying network support to achieve seamless presentation, processing, and delivery of immersive telepresence content at a large scale. Innovative design, rigorous validation, and testing exercises aim to fulfill the key technical requirements identified such as low-latency communication, high bandwidth demand, and complex content encoding/rendering tasks in real-time. The industry-leading SPIRIT consortium will build on the existing TRL4 application platforms and network infrastructures developed by the project partners, aiming to address key technical challenges and further develop all major aspects of telepresence technologies to achieve targeted TRL7. The SPIRIT Project will focus its innovations in network-layer, transport-layer, application/content-layer techniques, as well as security and privacy mechanisms to facilitate the large-scale operation of telepresence applications. The project team will develop a fully distributed, interconnected testing infrastructure across two geographical sites in Germany and UK, allowing large-scale testing of heterogeneous telepresence applications in real-life Internet environments. The network infrastructure will host two mainstream application
environments based on WebRTC and low-latency DASH. In addition to the project-designated use case scenarios, the project team will test a variety of additional use cases covering heterogeneous vertical sectors through FSTP participation.

Elsevier Computer Communications journal
Alireza Erfanian (Alpen-Adria-Universität Klagenfurt), Farzad Tashtarian (Alpen-Adria-Universität Klagenfurt), Christian Timmerer (Alpen-Adria-Universität Klagenfurt), and Hermann Hellwagner (Alpen-Adria-Universität Klagenfurt).
Abstract: Recent advances in embedded systems and communication technologies enable novel, non-safety applications in Vehicular Ad Hoc Networks (VANETs). Video streaming has become a popular core service for such applications. In this paper, we present QoCoVi as a QoE- and cost-aware adaptive video streaming approach for the Internet of Vehicles (IoV) to deliver video segments requested by mobile users at specified qualities and deadlines. Considering a multitude of transmission data sources with different capacities and costs, the goal of QoCoVi is to serve the desired video qualities with minimum costs. By applying Dynamic Adaptive Streaming over HTTP (DASH) principles, QoCoVi considers cached video segments on vehicles equipped with storage capacity as the lowest-cost sources for serving requests.
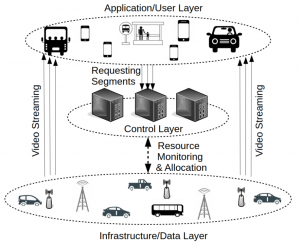 We design QoCoVi in two SDN-based operational modes: (i) centralized and (ii) distributed. In centralized mode, we can obtain a suitable solution by introducing a mixed-integer linear programming (MILP) optimization model that can be executed on the SDN controller. However, to cope with the computational overhead of the centralized approach in real IoV scenarios, we propose a fully distributed version of QoCoVi based on the proximal Jacobi alternating direction method of multipliers (ProxJ-ADMM) technique. The effectiveness of the proposed approach is confirmed through emulation with Mininet-WiFi in different scenarios.
We design QoCoVi in two SDN-based operational modes: (i) centralized and (ii) distributed. In centralized mode, we can obtain a suitable solution by introducing a mixed-integer linear programming (MILP) optimization model that can be executed on the SDN controller. However, to cope with the computational overhead of the centralized approach in real IoV scenarios, we propose a fully distributed version of QoCoVi based on the proximal Jacobi alternating direction method of multipliers (ProxJ-ADMM) technique. The effectiveness of the proposed approach is confirmed through emulation with Mininet-WiFi in different scenarios.
Every minute, more than 500 hours of video material are published on YouTube. These days, moving images account for a vast majority of data traffic, and there is no end in sight. This means that technologies that can improve the efficiency of video streaming are becoming all the more important. This is exactly what Hadi Amirpourazarian is working on in the Christian Doppler Laboratory ATHENA at the University of Klagenfurt. Read the full article here.


The new 5G standard will bring data centers closer to the customer. ITEC researchers are developing a system for the rapid distribution of computing tasks.
The newspaper “Der Standard” reported and published the article “Verteiltes Rechnen dank Fog-Computings“.
The kick-off meeting of the FF4EuroHPC Project “CardioHPC” took place online on Friday, March 11, 2022. The purpose of this first meeting was primarily the definition of work structures, work packages, and getting to know each partner region. The project partners consist of the following institutions: INNO, Ss. Cyril and Methodius University, Skopjee, and Klagenfurt University
Electronic health records, like ELGA in Austria, provide an overview of laboratory results, diagnostics and therapies. Much could be learned from the personal and private data of individuals – with the help of machine learning – for use in the treatment of others. However, the use of the data is a delicate matter, especially when it comes to diseases that carry a stigma. Researchers involved in the EU project “Enabling the Big Data Pipeline Lifecycle on the Computing Continuum (DataCloud)” are working to make new forms of information processing suitable for medical purposes. Dragi Kimovski and his colleagues recently presented their findings in a publication. Read the complete article here.