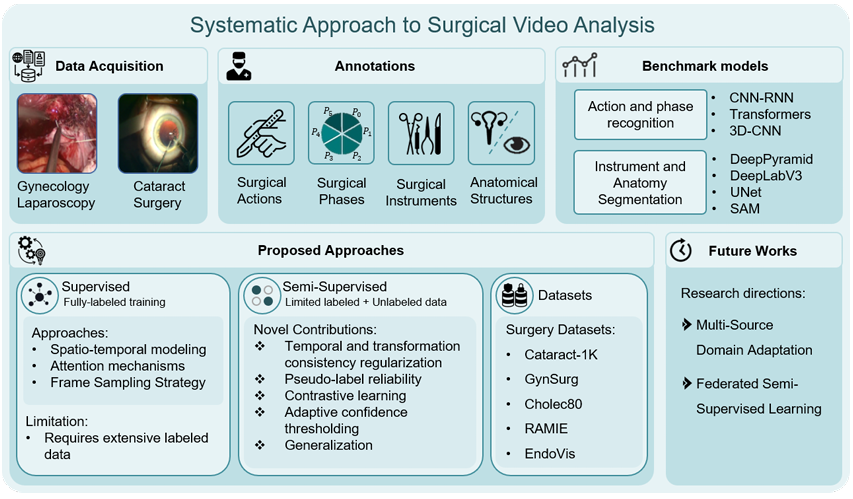
Paper Title: STEP-MR: A Subjective Testing and Eye-Tracking Platform for Dynamic Point Clouds in Mixed Reality
Conference Details: 32nd International Conference on Multimedia Modeling; Jan 29 – Jan 31, 2026; Prague, Czech Republic
Authors: Shivi Vats (AAU, Austria), Christian Timmerer (AAU, Austria), Hermann Hellwagner (AAU, Austria)
Abstract:
The use of point cloud (PC) streaming in mixed reality (MR) environments is of particular interest due to the immersiveness and the six degrees of freedom (6DoF) provided by the 3D content. However, this immersiveness requires significant bandwidth. Innovative solutions have been developed to address these challenges, such as PC compression and/or spatially tiling the PC to stream different portions at different quality levels. This paper presents a brief overview of a Subjective Testing and Eye-tracking Platform for dynamic point clouds in Mixed Reality (STEP-MR) for the Microsoft HoloLens 2. STEP-MR was used to conduct subjective tests (described in [1]) with 41 participants, yielding over 2000 responses and more than 150 visual attention maps, the results of which can be used, among other things, to improve dynamic (animated) point cloud streaming solutions mentioned above. Building on our previous platform, the new version now enables eye-tracking tests, including calibration and heatmap generation. Additionally, STEP-MR features modifications to the subjective tests’ functionality, such as a new rating scale and adaptability to participant movement during the tests, along with other user experience changes.