
You are a Master Student and want to get to know more about ATHENA in a 3 months ATHENA internship in 2022?
Come and join our team! Apply now.
(Please note: application deadline is 14 December 2021)

You are a Master Student and want to get to know more about ATHENA in a 3 months ATHENA internship in 2022?
Come and join our team! Apply now.
(Please note: application deadline is 14 December 2021)

Title: FSpot: Fast Multi-Objective Heuristic for Efficient Video Encoding Workloads over AWS EC2 Spot Instance Fleet
Authors: Anatoliy Zabrovskiy, Prateek Agrawal, Vladislav Kashansky, Roland Kersche, Christian Timmerer, and Radu Prodan
Abstract: HTTP Adaptive Streaming (HAS) of video content is becoming an undivided part of the Internet and accounts for most of today’s network traffic. Video compression technology plays a vital role in efficiently utilizing network channels, but encoding videos into multiple representations with selected encoding parameters is a significant challenge. However, video encoding is a computationally intensive and time-consuming operation that requires high-performance resources provided by on-premise infrastructures or public clouds. In turn, the public clouds, such as Amazon elastic compute cloud (EC2), provide hundreds of computing instances optimized for different purposes and clients’ budgets. Thus, there is a need for algorithms and methods for optimized computing instance selection for specific tasks such as video encoding and transcoding operations. Additionally, the encoding speed directly depends on the selected encoding parameters and the complexity characteristics of video content. In this paper, we first benchmarked the video encoding performance of Amazon EC2 spot instances using multiple x264 codec encoding parameters and video sequences of varying complexity. Then, we proposed a novel fast approach to optimize Amazon EC2 spot instances and minimize video encoding costs. Furthermore, we evaluated how the optimized selection of EC2 spot instances can affect the encoding cost. The results show that our approach, on average, can reduce the encoding costs by at least 15.8% and up to 47.8% when compared to a random selection of EC2 spot instances.
Keywords: EC2 Spot instance, Encoding time prediction; adaptive streaming; video transcoding; Clustering; HTTP adaptive streaming; MPEG-DASH; Cloud computing; optimization; Pareto front.
Title: Monitoring System Architecture for the Multi-Scale Blockchain-based Logistic Network
Authors: Vladislav Kashansky, Radu Prodan, Aso Validi, Cristina Olaverri-Monreal, Gleb Radchenko
Abstract: Contemporary control processes and methods in multi-scale, cyber-physical systems require precise data collection at various levels, timely transmission, and analysis involving large number of computing and storage elements connected within high-performance permissioned consensus networks. For example, in transport networks, resources tend to form multi-scale dynamical systems with diverse operational requirements, including data exchange policies and consensus protocols. Apart from designing complete topology, chaincodes and consensus logic, effective monitoring of the applications and infrastructure of such complex systems remains a research challenge. In this paper, we discuss important aspects of the data-intensive applications monitoring investigated in the frames of the ADAPT project.
We present highlights on the tool-sets, architectures and details on possible optimization approaches for monitoring data collection. We introduce a dynamic multi-scale monitoring system architecture with preliminary workflow model. It allows obtaining effective low-latency publish-subscribe matching of the dynamically varying monitoring tasks and executing machines.
Keywords: Logistics, transportation, decentralization, blockchain, monitoring systems, optimization, data-intensive systems, hybrid systems

Farzad Tashtarian is invited to talk on “Network-Assisted Video Streaming” at the University of Isfahan, Isfahan, Iran.

Dr. Gerhard Burian and Mag. Vladislav Kashansky participated on behalf of ADAPT collaboration in the international conference: Climate protection: state of play, division of labor, steps forward held at OeNB, Vienna on 07.10.2021.
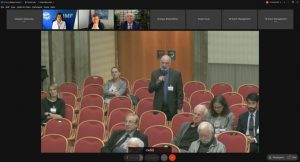

The first face-to-face DataCloud Meeting took place in Rome, Italy, from October 04-06, 2021. The consortium discussed the architecture and the business cases in preparation for the first project review.


Ekrem Çetinkaya got the Best Doctoral Symposium Paper Award at ACM MMSys 2021 for his paper titled “Machine Learning Based Video Coding Enhancements for HTTP Adaptive Streaming”. More information about the paper can be found HERE.


The first face-to-face ARTICONF Meeting after the pandemic, hosted by Agilia, took place from September 21-24, 2021, in Seville, Spain. The consortium discussed the advancements and progress made this year and listed down strategies for validating and exploiting ARTICONF use cases through real-world testing and external collaboration amid pandemics. In addition, ARTICONF’s technical team addressed existing integration concerns and stressed to finalize the prototype in the coming months. The consortium further pledged to continue its ongoing efforts in disseminating ARTICONF scientific results at high-ranked venues.


The H2020 project ASPIDE impressed the reviewers with the presented scientific achievements in Exascale computing and passed the final EC review with flying colors. The project officer and reviewers echoed the effort put together by the consortium partners for publicly demonstrating and sharing the ASPIDE tools while maintaining a robust scientific output at the highest level. The EC reviewers gave very positive input on the scientific tools developed within WP3, which Klagenfurt University led.
On 10 September 2021, ADAPT project was represented at the GOODIT´21 conference in Rome, Italy by Vladislav Kashanskii.
Here you find his presentation about “The ADAPT Project: Adaptive and Autonomous Data Performance Connectivity and Decentralized Transport Decision-Making Network” as pdf and video.