IEEE Access, A Multidisciplinary, Open-access Journal of the IEEE
[PDF]
Minh Nguyen (Christian Doppler Laboratory ATHENA, Alpen-Adria-Universität Klagenfurt), Daniele Lorenzi (Christian Doppler Laboratory ATHENA, Alpen-Adria-Universität Klagenfurt), Farzad Tashtarian (Christian Doppler Laboratory ATHENA, Alpen-Adria-Universität Klagenfurt), Hermann Hellwagner (Christian Doppler Laboratory ATHENA, Alpen-Adria-Universität Klagenfurt), Christian Timmerer (Christian Doppler Laboratory ATHENA, Alpen-Adria-Universität Klagenfurt)
(*) Minh Nguyen and Daniele Lorenzi contributed equally to this work
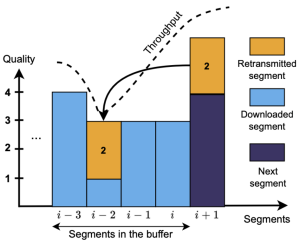
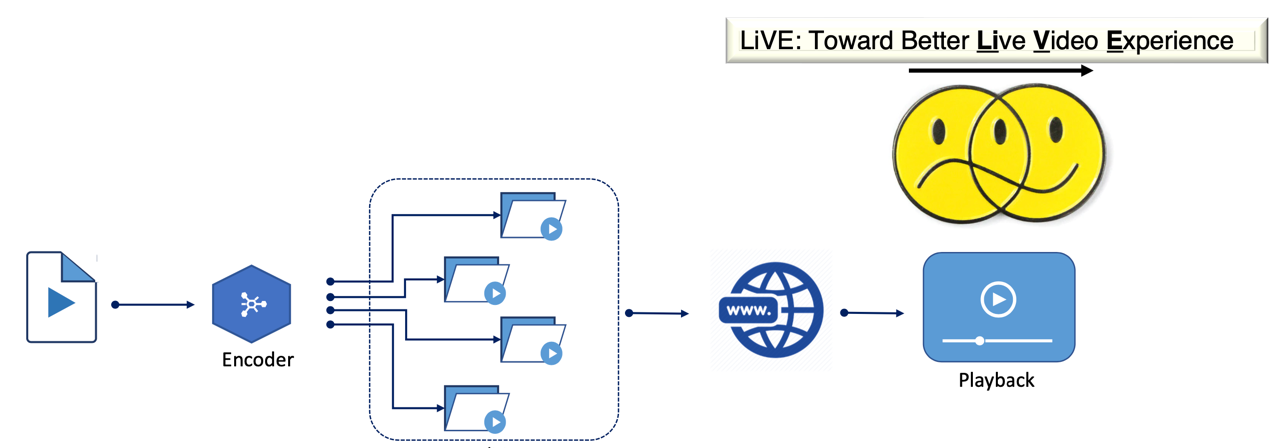
Abstract: HTTP Adaptive Streaming (HAS) solutions use various adaptive bitrate (ABR) algorithms to select suitable video qualities with the objective of coping with the variations of network connections. HTTP has been evolving with various versions and provides more and more features. Most of the existing ABR algorithms do not significantly benefit from the HTTP development when they are merely supported by the most recent HTTP version. An open research question is “How can new features of the recent HTTP versions be used to enhance the performance of HAS?” To address this question, in this paper, we introduce Days of Future Past+ (DoFP+ for short), a heuristic algorithm that takes advantage of the features of the latest HTTP version, HTTP/3, to provide high Quality of Experience (QoE) to the viewers. DoFP+ leverages HTTP/3 features, including (i) stream multiplexing, (ii) stream priority, and (iii) request cancellation to upgrade low-quality segments in the player buffer while downloading the next segment. The qualities of those segments are selected based on an objective function and throughput constraints. The objective function takes into account two factors, namely the (i) average bitrate and the (ii) video instability of the considered set of segments. We also examine different strategies of download order for those segments to optimize the QoE in limited resources scenarios. The experimental results show an improvement in QoE by up to 33% while the number of stalls and stall duration for DoFP+ are reduced by 86% and 92%, respectively, compared to state-of-the-art ABR schemes. In addition, DoFP+ saves on average up to 16% downloaded data across all test videos. Also, we find that downloading segments sequentially brings more benefits for retransmissions than concurrent downloads; and lower-quality segments should be upgraded before other segments to gain more QoE improvement. Our source code has been published for reproducibility at https://github.com/cd-athena/DoFP-Plus.
Keywords: HTTP/3, ABR algorithm, QoE, HAS, DASH