

Paper accepted – Light-weight Video Encoding Complexity Prediction using Spatio Temporal Features
2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP)
September 26-28, 2022 | Shanghai, China
Conference Website
Hadi Amirpour (Alpen-Adria-Universität Klagenfurt), Prajit T Rajendran (Universite Paris-Saclay, Paris, France), Vignesh V Menon (Alpen-Adria-Universität Klagenfurt), Mohammad Ghanbari (School of Computer Science and Electronic Engineering, University of Essex, Colchester, UK), and Christian Timmerer (Alpen-Adria-Universität Klagenfurt)
Abstract:
The increasing demand for high-quality and low-cost video streaming services calls for the prediction of video encoding complexity. The prior prediction of video encoding complexity including encoding time and bitrate predictions are used to allocate resources and set optimized parameters for video encoding effectively. In this paper, a light-weight video encoding complexity prediction (VECP) scheme that predicts the encoding bitrate and the encoding time of video with high accuracy is proposed. Firstly, low-complexity Discrete Cosine Transform (DCT)-energy-based features, namely spatial complexity, temporal complexity, and brightness of videos are extracted, which can efficiently
represent the encoding complexity of videos. The latent vectors are also extracted from a Convolutional Neural Network (CNN) with MobileNet as the backend to obtain additional features from representative frames of each video to assist the prediction process. The extreme gradient boosting (XGBoost) regression algorithm is deployed to predict video encoding complexity using the extracted features. The experimental results demonstrate that VECP predicts the encoding bitrate with an error percentage of up to 3.47% and encoding time with an error percentage of up to 2.89%, but with a significantly low overall latency of 3.5 milliseconds per frame which makes it suitable for both Video on Demand (VoD) and live streaming applications.
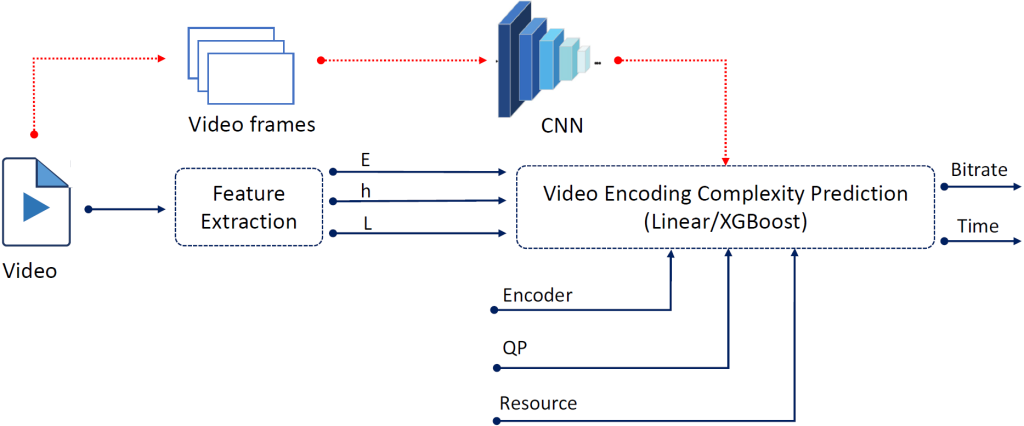
VECP architecture