Transactions on Multimedia Computing Communications and Applications (TOMM)
Vignesh V Menon (Alpen-Adria-Universität Klagenfurt), Hadi Amirpour (Alpen-Adria-Universität Klagenfurt), Mohammad Ghanbari (School of Computer Science and Electronic Engineering, University of Essex, Colchester, UK), and Christian Timmerer (Alpen-Adria-Universität Klagenfurt)
Abstract:
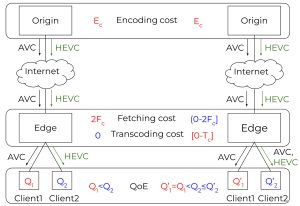
In HTTP Adaptive Streaming (HAS), videos are encoded at multiple bitrates and spatial resolutions (i.e., representations) to adapt to the heterogeneity of network conditions, device attributes, and end-user preferences. Encoding the same video segment at
multiple representations increases costs for content providers. State-of-the-art multi-encoding schemes improve the encoding process by utilizing encoder analysis information from already encoded representation(s) to reduce the encoding time of the remaining
representations. These schemes typically use the highest bitrate representation as the reference to accelerate the encoding of the remaining representations. Nowadays, most streaming services utilize cloud-based encoding techniques, enabling a fully parallel
encoding process to reduce the overall encoding time. The highest bitrate representation has the highest encoding time than the other representations. Thus, utilizing it as the reference encoding is unfavorable in a parallel encoding setup as the overall encoding time is bound by its encoding time. This paper provides a comprehensive study of various multi-rate and multi-encoding schemes in both serial and parallel encoding scenarios. Furthermore, it introduces novel heuristics to limit the Rate Distortion Optimization (RDO) process across various representations. Based on these heuristics, three multi-encoding schemes are proposed, which rely on encoder analysis sharing across different representations: (i) optimized for the highest compression efficiency, (ii) optimized for the best compression efficiency-encoding time savings trade-off, and (iii) optimized for the best encoding time savings. Experimental results demonstrate that the proposed multi-encoding schemes (i), (ii), and (iii) reduce the overall serial encoding time by 34.71%, 45.27%, and 68.76% with a 2.3%, 3.1%, and 4.5% bitrate increase to maintain the same VMAF, respectively compared to stand-alone encodings. The overall parallel encoding time is reduced by 22.03%, 20.72%, and 76.82% compared to stand-alone encodings for schemes (i), (ii), and (iii), respectively.
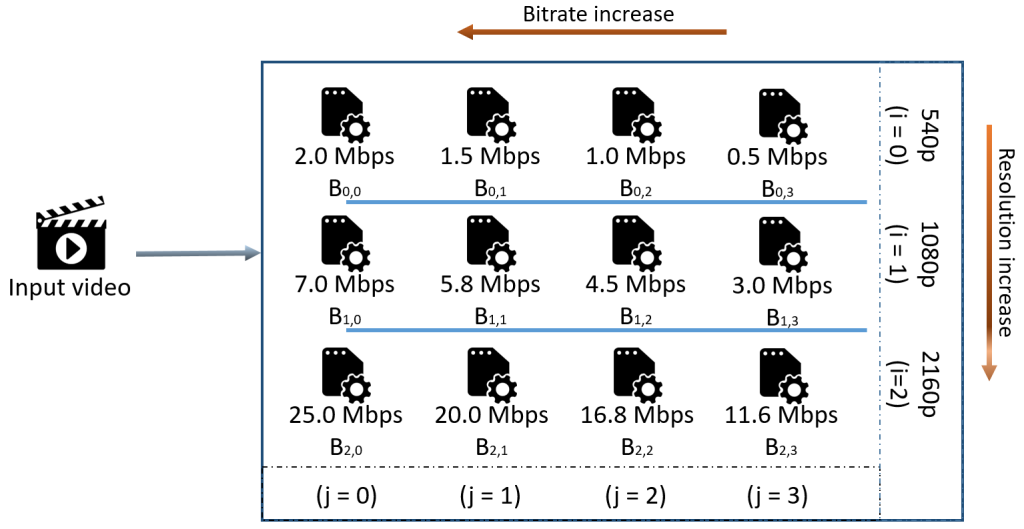
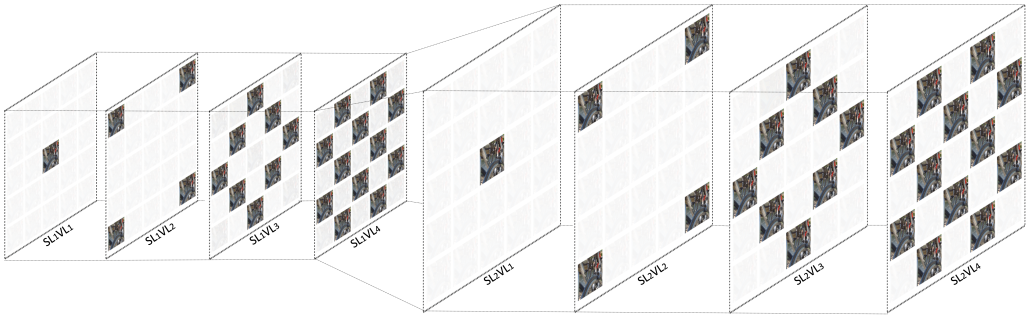
An example of video representations’ storage in HAS. The input video is encoded at multiple resolutions and bitrates. Novel multi-rate and multi-resolution encoder
analysis sharing methods are presented to accelerate encoding in more than one representation.