The paper “Two-pass Encoding for Live Video Streaming” has been selected as the Best Student Paper at the NAB Broadcast Engineering and IT (BEIT) Conference 2025.
NAB Broadcast Engineering and IT (BEIT) Conference
5–9 April 2025 | Las Vegas, NV, USA
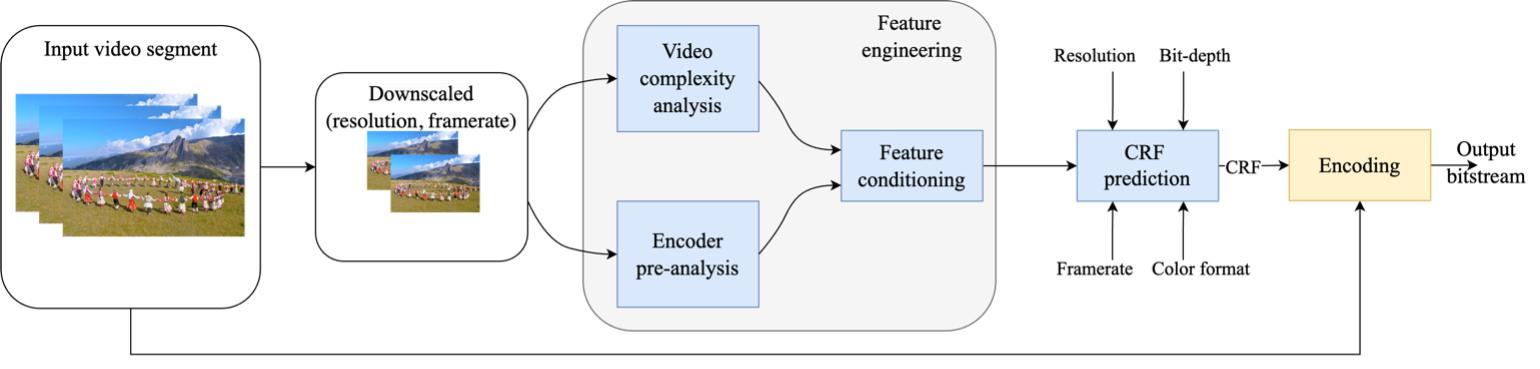
Abstract: Live streaming has become increasingly important in our daily lives due to the growing demand for real-time content consumption. Traditional live video streaming typically relies on single-pass encoding due to its low latency. However, it lacks video content analysis, often resulting in inefficient compression and quality fluctuations during playback. Constant Rate Factor (CRF) encoding, a type of single-pass method, offers more consistent quality but suffers from unpredictable output bitrate, complicating bandwidth management. In contrast, multi-pass encoding improves compression efficiency through multiple passes. However, its added latency makes it unsuitable for live streaming. In this paper, we propose OTPS, an online two-pass encoding scheme that overcomes these limitations by employing fast feature extraction on a downscaled video representation and a gradient-boosting regression model to predict the optimal CRF for encoding. This approach provides consistent quality and efficient encoding while avoiding the latency introduced by traditional multi-pass techniques. Experimental results show that OTPS offers 3.7% higher compression efficiency than single-pass encoding and achieves up to 28.1% faster encoding than multi-pass modes. Compared to single-pass encoding, encoded videos using OTPS exhibit 5% less deviation from the target bitrate while delivering notably more consistent quality.
Authors: Mohammad Ghasempour (AAU, Austria); Hadi Amirpour (AAU, Austria); Christian Timmerer (AAU, Austria)