The seminar talks every two weeks are co-organized together with the research group of Networks and Distributed Computing at the University of Liverpool, as part of the Durham-Liverpool synergy. The contact person of this synergy in Liverpool is Leszek Gasieniec.
The seminar talks will be streamed online on zoom. Whenever the speaker is physically present in Durham, the presentation will also be in the Vis-Lab at the 1st floor of the MCS building (in addition to zoom streaming). Please refer to the schedule below for any room changes at some selected talks.
NESTiD Seminar Coordinator: George Mertzios
Title: Extreme and Sustainable Graph Processing for Urgent Societal Challenges in Europe: The Graph-Massivizer project
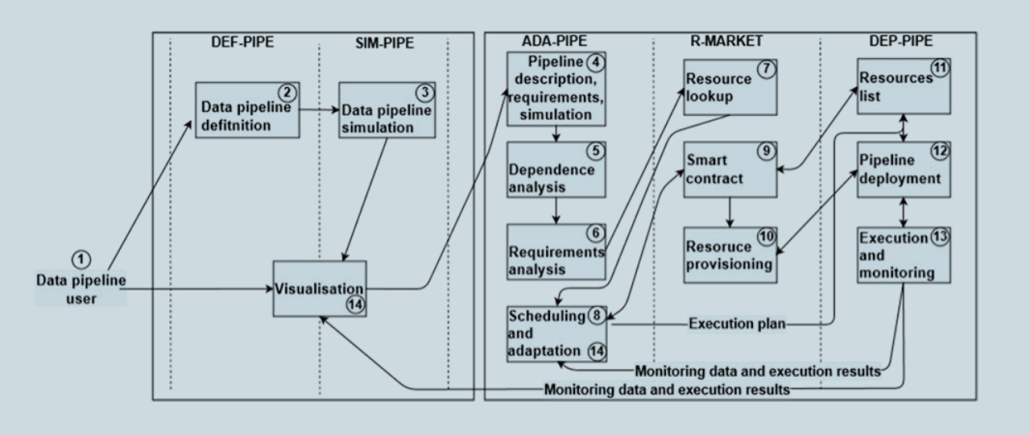
Abstract: Graph-Massivizer is a Horizon Europe project that researches and develops a high-performance, scalable, and sustainable platform for information processing and reasoning based on the massive graph representation of extreme data. It delivers a toolkit of five open-source software tools and FAIR graph datasets covering the sustainable lifecycle of processing extreme data as massive graphs. The tools focus on holistic usability (from extreme data ingestion and massive graph creation), automated intelligence (through analytics and reasoning), performance modelling, and environmental sustainability tradeoffs, supported by credible data-driven evidence across the computing continuum. The automated operation based on the emerging serverless computing paradigm supports experienced and novice stakeholders from a broad group of large and small organisations to capitalise on extreme data through massive graph programming and processing. Graph Massivizer validates its innovation on four complementary use cases considering their extreme data properties and coverage of the three sustainability pillars (economy, society, and environment): sustainable green finance, global environment protection foresight, green AI for the sustainable automotive industry, and data centre digital twin for exascale computing. Graph Massivizer promises 70% more efficient analytics than AliGraph, and 30% improved energy awareness for ETL storage operations than Amazon Redshift. Furthermore, it aims to demonstrate a possible two-fold improvement in data centre energy efficiency and over 25% lower GHG emissions for basic graph operations. Graph-Massivizer gathers an interdisciplinary group of twelve partners from eight countries, covering four academic universities, two applied research centres, one HPC centre, two SMEs and two large enterprises. It leverages the world-leading roles of European researchers in graph processing and serverless computing and uses leadership-class European infrastructure in the computing continuum.
 Alpen-Adria Universität Klagenfurt, Institute of Information Technology Chinese Academy of Sciences, Institute of Automation Johannes-Kepler-Universität Linz, Intelligent Transport Systems- Sustainable Transport Logistics 4.0 Logoplan – Logistik, Verkehrs und Umweltschutz Consulting GmbH Intact GmbH Chinese Academy of Sciences, Institute of Computing Technology
Alpen-Adria Universität Klagenfurt, Institute of Information Technology Chinese Academy of Sciences, Institute of Automation Johannes-Kepler-Universität Linz, Intelligent Transport Systems- Sustainable Transport Logistics 4.0 Logoplan – Logistik, Verkehrs und Umweltschutz Consulting GmbH Intact GmbH Chinese Academy of Sciences, Institute of Computing Technology
 Radu Prodan presented the Graph-Massivizer project at the CERCIRAS COST action on 7th February in Gdansk, Poland
Radu Prodan presented the Graph-Massivizer project at the CERCIRAS COST action on 7th February in Gdansk, Poland