

Magazine article published: DataCloud: Resource provisioning, scheduling and deployment of big-data pipelines
HiPEAC magazine https://www.hipeac.net/news/#/magazine/
HiPEACINFO 68, pages 27-28.
Autohrs: Dragi Kimovski (Alpen-Adria-Universität Klagenfurt, Austria), Narges Mehran (Alpen-Adria-Universität Klagenfurt, Austria), Radu Prodan (Alpen-Adria-Universität Klagenfurt, Austria), Souvik Sengupta (iExec Blockchain Tech, France), Anthony Simonet-Boulgone (iExec Blockchain Tech, France), Ioannis Plakas (UBITECH, Greece) , Giannis Ledakis (UBITECH, Greece) and Dumitru Roman (University of Oslo and SINTEF AS, Norway)
Abstract: Modern big-data pipeline applications, such as machine learning, encompass complex workflows for real-time data gathering, storage and analysis. Big-data pipelines often have conflicting requirements, such as low communication latency and high computational speed. These require different kinds of computing resource, from cloud to edge, distributed across multiple geographical locations – in other words, the computing continuum. The Horizon 2020 DataCloud project is creating a novel paradigm for big-data pipeline processing over the computing continuum, covering the complete lifecycle of bigdata pipelines. To overcome the runtime challenges associated with automating big-data pipeline processing on the computing continuum, we’ve created the DataCloud architecture. By separating the discovery, definition, and simulation of big-data pipelines from runtime execution, this architecture empowers domain experts with little infrastructure or software knowledge to take an active part in defining big-data pipelines.
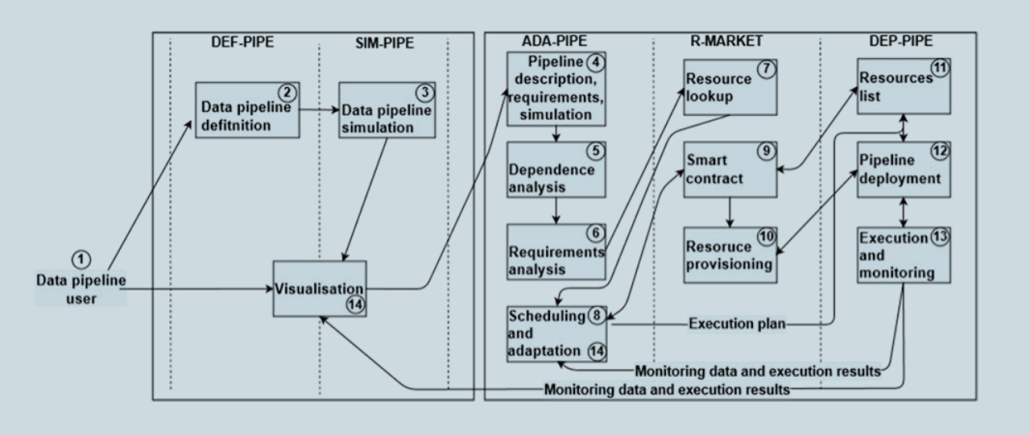
This work received funding from the DataCloud European Union’s Horizon 2020 research and innovation programme under grant agreement no. 101016835.