CLIP-DQA: Blindly Evaluating Dehazed Images from Global and Local Perspectives Using CLIP
The IEEE International Symposium on Circuits and Systems (IEEE ISCAS 2025)
25–28 May 2025 // London, United Kingdom
Yirui Zeng (Cardiff University, UK), Jun Fu (Cardiff University), Hadi Amirpour (AAU, Austria), Huasheng Wang (Alibaba Group), Guanghui Yue (Shenzhen University, China), Hantao Liu (Cardiff University), Ying Chen (Alibaba Group), Wei Zhou (Cardiff University)
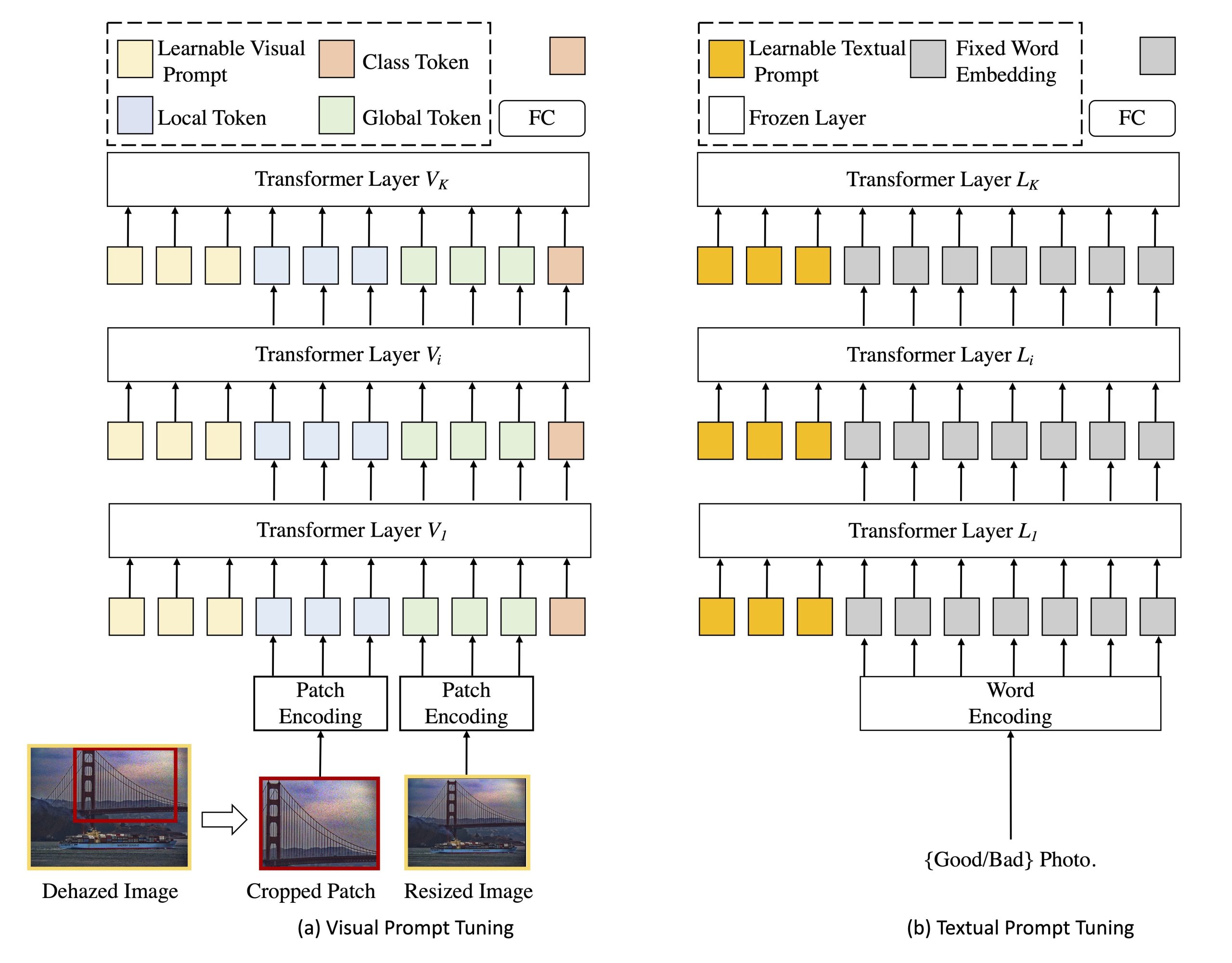
Abstract: Blind dehazed image quality assessment (BDQA), which aims to accurately predict the visual quality of dehazed images without any reference information, is essential for the evaluation, comparison, and optimization of image dehazing algorithms. Existing learning-based BDQA methods have achieved remarkable success, while the small scale of DQA datasets limits their performance. To address this issue, in this paper, we propose to adapt Contrastive Language-Image Pre-Training (CLIP), pre-trained on large-scale image-text pairs, to the BDQA task. Specifically, inspired by the fact that the human visual system understands images based on hierarchical features, we take global and local information of the dehazed image as the input of CLIP. To accurately map the input hierarchical information of dehazed images into the quality score, we tune both the vision branch and language branch of CLIP with prompt learning. Experimental results on two authentic DQA datasets demonstrate that our proposed approach, named CLIP-DQA, achieves more accurate quality predictions over existing BDQA methods.