SIGMM Records Column
Samira Afzal (Alpen-Adria-Universität (AAU) Klagenfurt, Austria), Radu Prodan (Alpen-Adria-Universität (AAU) Klagenfurt, Austria), Christian Timmerer (Alpen-Adria-Universität (AAU) Klagenfurt and Bitmovin Inc., Austria)
Introduction:
Regarding the Intergovernmental Panel on Climate Change (IPCC) report in 2021 and Sustainable Development Goal (SDG) 13 “climate action”, urgent action is needed against climate change and global greenhouse gas (GHG) emissions in the next few years [1]. This urgency also applies to the energy consumption of digital technologies. Internet data traffic is responsible for more than half of digital technology’s global impact, which is 55% of energy consumption annually. The Shift Project forecast [2] shows an increase of 25% in data traffic associated with 9% more energy consumption per year, reaching 8% of all GHG emissions in 2025.
Video flows represented 80% of global data flows in 2018, and this video data volume is increasing by 80% annually [2]. This exponential increase in the use of streaming video is due to (i) improvements in Internet connections and service offerings [3], (ii) the rapid development of video entertainment (e.g., video games and cloud gaming services), (iii) the deployment of Ultra High-Definition (UHD, 4K, 8K), Virtual Reality (VR), and Augmented Reality (AR), and (iv) an increasing number of video surveillance and IoT applications [4]. Interestingly, video processing and streaming generate 306 million tons of CO2, which is 20% of digital technology’s total GHG emissions and nearly 1% of worldwide GHG emissions [2].
While research has shown that the carbon footprint of video streaming has been decreasing in recent years [5], there is still a high need to invest in research and development of efficient next-generation computing and communication technologies for video processing technologies. This carbon footprint reduction is due to technology efficiency trends in cloud computing (e.g., renewable power), emerging modern mobile networks (e.g., growth in Internet speed), and end-user devices (e.g., users prefer less energy-intensive mobile and tablet devices over larger PCs and laptops). However, since the demand for video streaming is growing dramatically, it raises the risk of increased energy consumption.
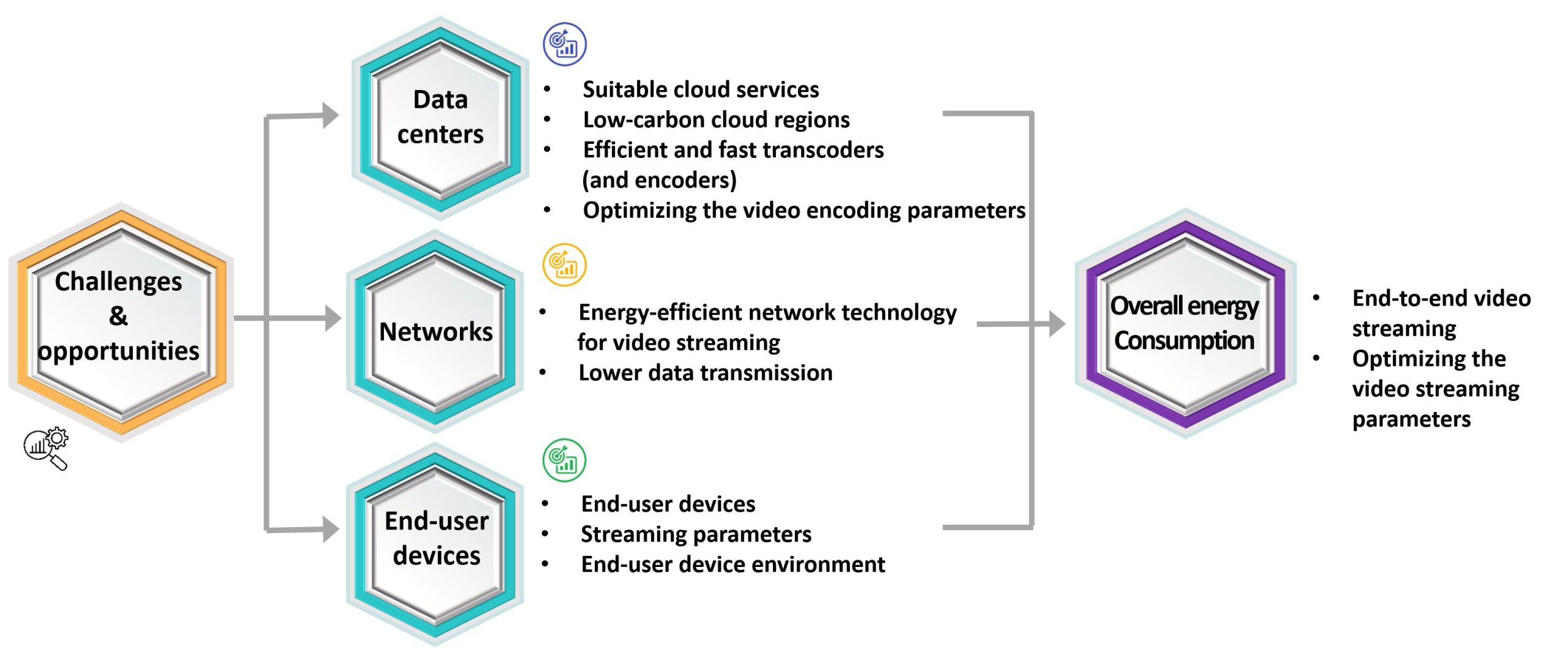
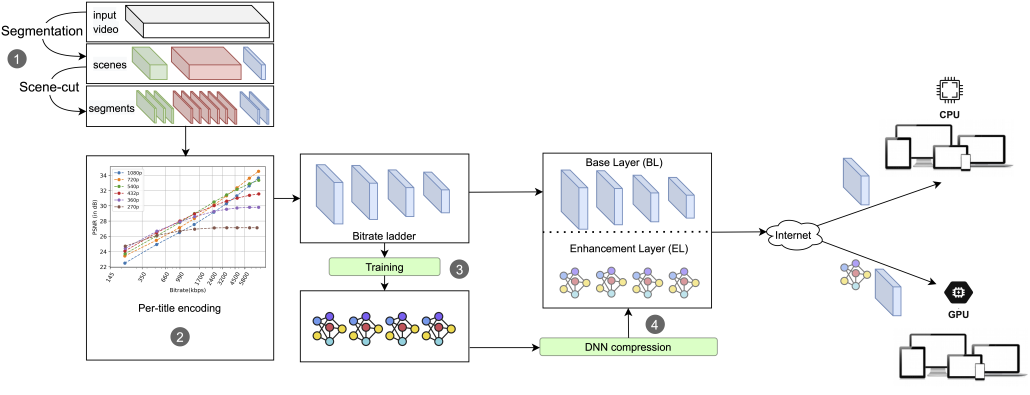
Investigating energy efficiency during video streaming is essential to developing sustainable video technologies. The processes from video encoding to decoding and displaying the video on the end user’s screen require electricity, which results in CO2 emissions. Consequently, the key question becomes: “How can we improve energy efficiency for video streaming systems while maintaining an acceptable Quality of Experience (QoE)?”.