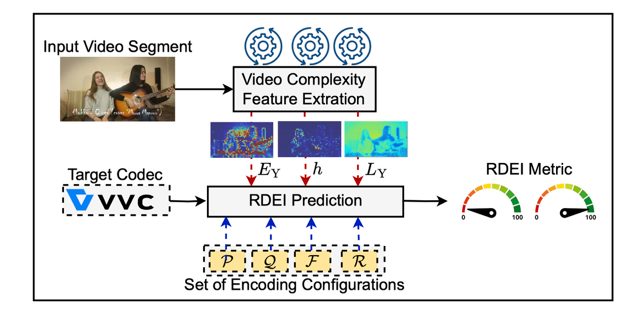
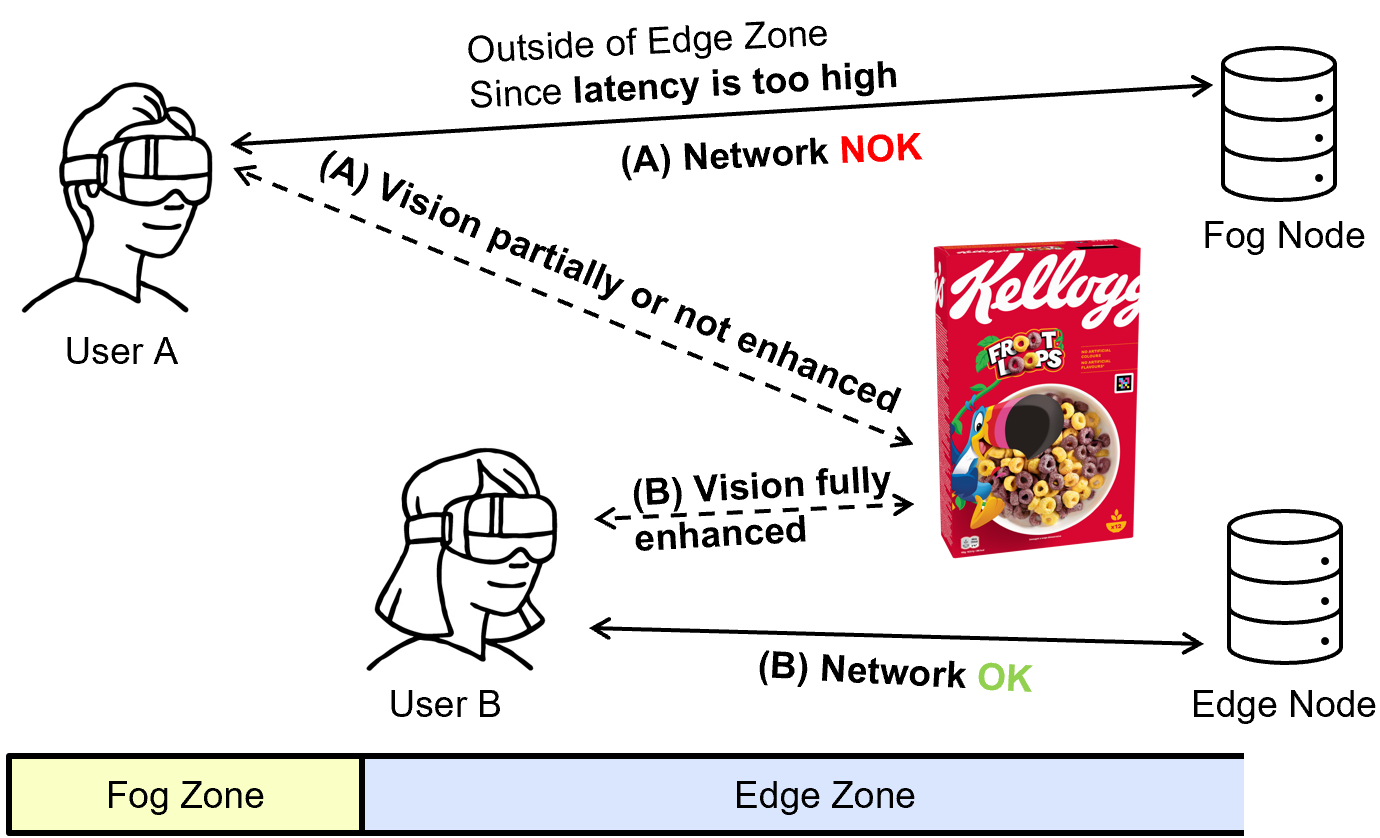
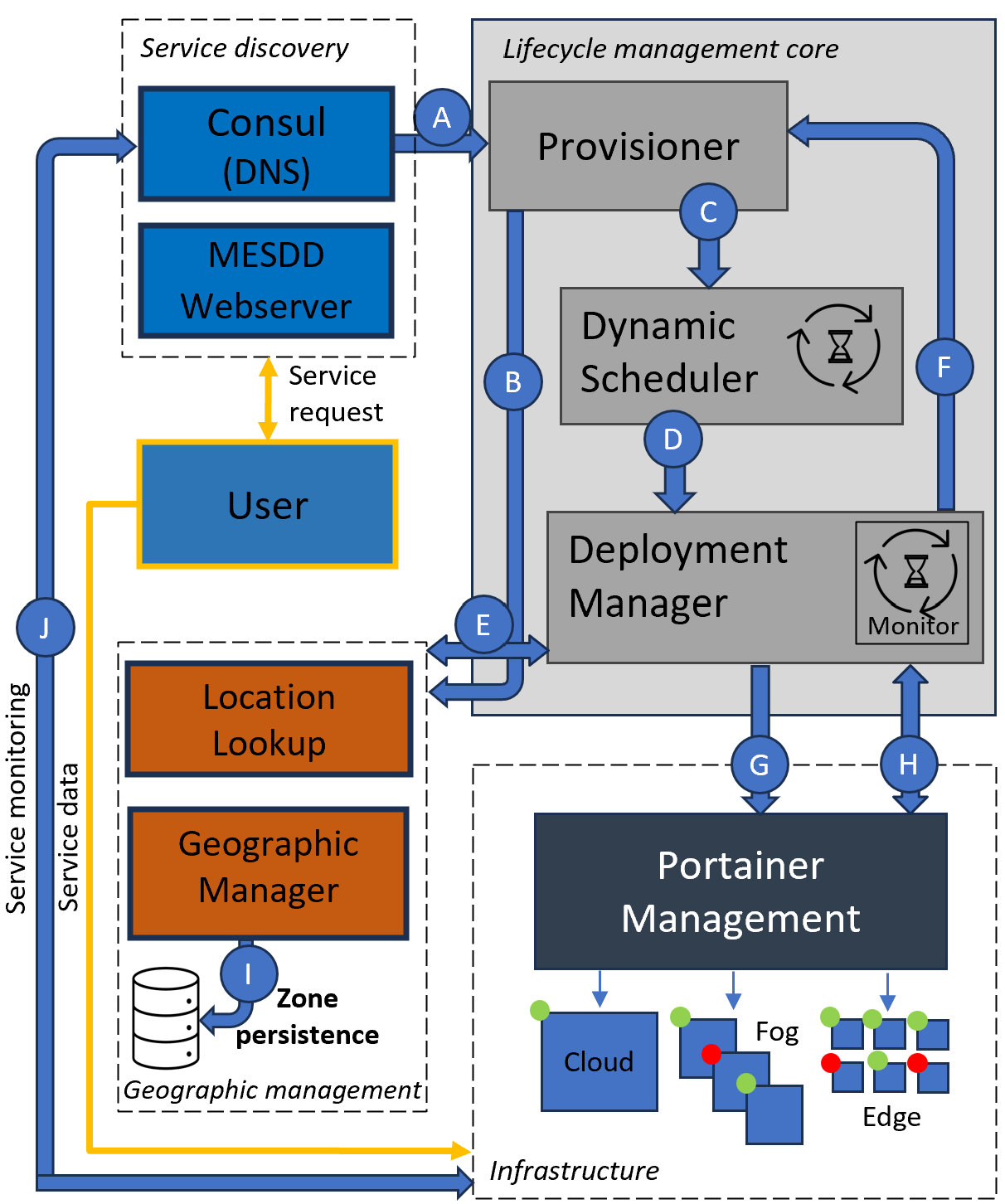
Dr. Reza Farahani presented 3-hour tutorial titled “Serverless Orchestration on the Edge-Cloud Continuum: Challenges and Solutions” at the 16th ACM/SPEC International Conference on Performance Engineering (ICPE) on May 5.
Abstract: Serverless computing simplifies application development by abstracting infrastructure management, allowing developers to focus on building application functionality while infrastructure providers handle tasks, such as resource scaling and provisioning. Orchestrating serverless applications across the edge-cloud continuum, however, poses challenges such as managing heterogeneous resources with varying computational capacities and energy constraints, ensuring low-latency execution, dynamically allocating workloads based on real-time metrics, and maintaining fault tolerance and scalability across multiple edge and cloud instances. This tutorial first explores foundational serverless computing concepts, including Function-as-a-Service (FaaS), Backend-as-a-Service (BaaS), and their integration into distributed edge-cloud systems. It then introduces advancements in multi-cloud orchestration, edge-cloud integration strategies, and resource allocation techniques, focusing on their applicability in real-world scenarios. It addresses the challenges of orchestrating serverless applications across edge-cloud environments, mainly using dynamic workload distribution models, multi-objective scheduling algorithms, and energy-optimized orchestration. Practical demonstrations employ Kubernetes, serverless platforms such as GCP Functions, AWS Lambda, AWS Step Functions, OpenFaaS, and OpenWhisk, along with monitoring tools like Prometheus and Grafana, to deploy and execute real-world application workflows, providing participants with hands-on experience and insights into evaluating and refining energy- and performance-aware serverless orchestration strategies.