Authors: Samira Afzal (Baylor University), Narges Mehran (Salzburg Research Forschungsgesellschaft mbH), Farzad Tashtarian (AAU, Austria), Andrew C. Freeman (Baylor University), Radu Prodan (University of Innsbruck), Christian Timmerer (AAU, Austria)
Venue: IEEE VCIP 2025, December 1 – December 4, 2025, Klagenfurt, Austria
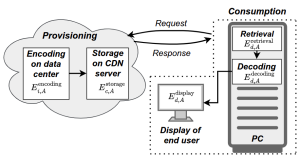
Abstract: The environmental impact of video streaming is gaining more attention due to its growing share in global internet traffic and energy consumption. To support accurate and transparent sustainability assessments, we present SEED (Streaming Energy and Emission Dataset)}: an open dataset for estimating energy usage and CO2 emissions in adaptive video streaming. SEED comprises over 500 video segments. It provides segment-level measurements of energy consumption and emissions for two primary stages: provisioning, which encompasses encoding and storage on cloud infrastructure, and end-user consumption, including network interface retrieval, video decoding, and display on end-user devices. The dataset covers multiple codecs (AVC, HEVC), resolutions, bitrates, cloud instance types, and geographic regions, reflecting real-world variations in computing efficiency and regional carbon intensity. By combining empirical benchmarks with component-level energy models, \dataset{} enables detailed analysis and supports the development of energy- and emission-aware adaptive bitrate (ABR) algorithms. The dataset is publicly available at: https://github.com/cd-athena/SEED.
SEED is available at: https://github.com/cd-athena/SEED